链表
链表
如果你不想看
不,你必须看……
链表的定义
链表在物理层面上是不连续的。回顾下第一节课的这张图:
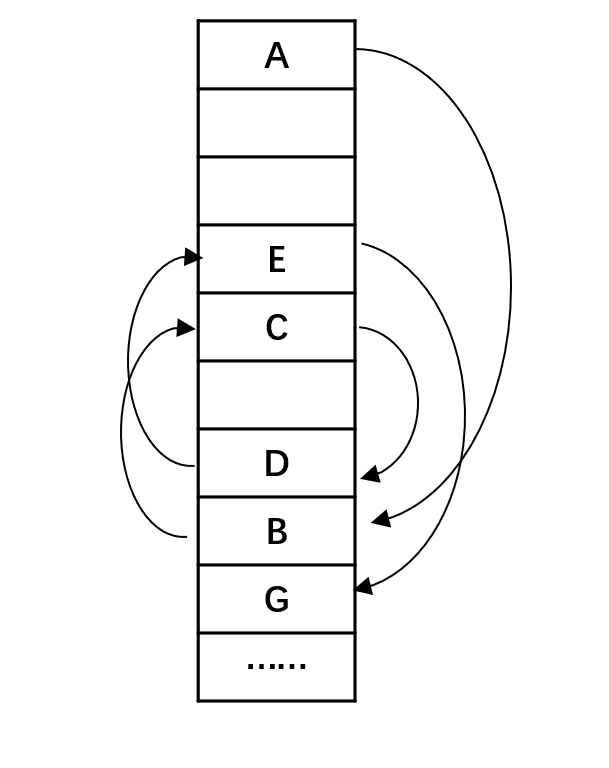
格子代表物理内存。
这里数据在逻辑上的次序是:
最后的^表示空指针,这在数据结构的图示中比较常见。
但从他的次序跟实际内存的位置并没有任何关系,所以他们关系仅在逻辑上成立。
那么要如何保证每个元素都能找到后续的元素呢?让每个元素都记住他们就可以了,最简单的方式是用指针指向他:
struct Node{
int value;
Node* next; // 指向下一个节点
}
这样每个元素都可以记住他的下一个节点,自然前后关系也可以建立起来了。
这就像串在一条绳上的珍珠,不管珍珠的位置如何变动。顺着绳子你总是可以把所有的珠子找出来:

必须指针吗?
这里要注意的是,虽然我们大多数情况(99.999%以上)下讨论的链表,或者说链式存储结构都采用指针来指向需要的元素,但这个指向也不是非指针不可。 例如我们可以用数组来模拟链表的实现:
struct Node{
int value;
int next;
}
在内存里数据的形式就如下图所示: 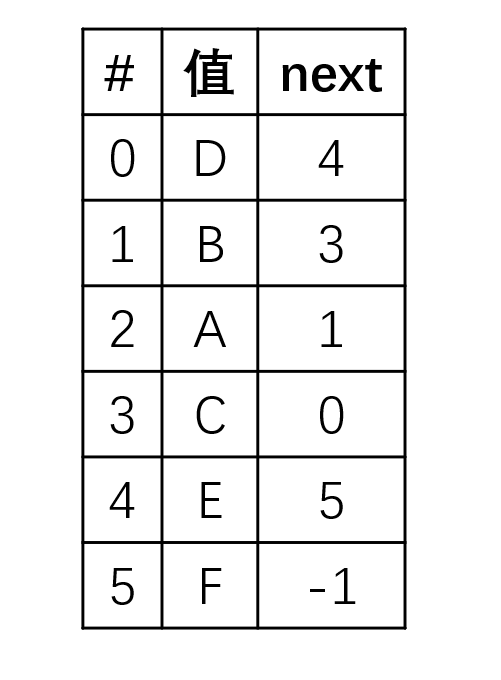 在
在next域里,放的不是指针而是对应的下标,我们一样可以用数组来实现链式存储。
不过我们课程的内容还是以指针式链表为准。
初始化、遍历和销毁
创建链表
初始化是相对简单的:
创建一个链表就是创建链表的节点。通过这个头节点,我们可以完成对链表的所有操作。
头节点就是链表,链表就是头节点
与顺序表不同,我们在讨论链表时,通常不会有一个专门的struct来表示这是一个链表,我们单纯的使用头节点来表示链表。
记住这点,后面要考。
为提高代码利用效率,我们统一用create_node来创建链表对象。头节点的创建也是用这个函数。
struct Node{
int value;
Node* next;
};
Node* create_node( int value){
Node* node = new Node;
node->value = value;
node->next = nullptr;
return node;
}
当然如果你有强迫症,需要区分创建节点和创建头节点,那么我们可以用函数调用的形式来获得create_list函数:
Node* create_list( int value ){
return create_node( value );
}
为什么我应该调用已有函数,而不是复制代码
回答很简单:因为这样是错的,ctrl+c和ctrl+v是编码的毒瘤之一,请一定要杜绝这个习惯。
我们至少有两个原因来阻止你这样做:
第一点:这带来代码长度的增长,代码长度的增长不仅会增大编译后程序的尺寸,也会增大编译这个程序所需要的时间。当然这点不是最重要的原因。
第二也是最重要的一点,这不符合软件工程的工作原则。
设想下,你把代码复制了多份,某天测试发现了其中的bug,你是不是需要把所有复制的区域都修改过来?当老板要你加入新需求时,是不是也要把所有复制的区域都重新修改一遍?
从工程化的另一个角度来说,这也会不必要地增加阅读代码的工作量,即便是上面这么短短的3行代码,花费的工作量也远大于一个命名规范的函数。
所以请记住:当你的手伸向ctrl+c时,一定要多问自己一句,能提炼一下吗?不管是函数还是宏,都比单纯的ctrl+c好!
遍历、尾插入和销毁
这三个操作有非常相似的处理方法,开始操作之前我们先建立链表:
Node* head = create_list( 1 );
Node* n2 = create_node(2);
Node* n3 = create_node(3);
Node* n4 = create_node(4);
head->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = nullptr;
通过这串代码我们建立了一个这样的链表:
假设我们要求遍历所有元素并打印其值,我们显然应该顺着next域一个一个地找过去,直到next域为空为止:
void print_list( Node* node ){
while(true){
cout << node->value << " ";
node = node->next;
if( node == nullptr )
break;
}
cout << endl;
}
当然有更简洁的写法:
void print_list( Node* node ){
while(node){
cout << node->value << " ";
node = node->next;
}
cout << endl;
}
或者:
void print_list( Node* node ){
for( ;node!=nullptr; node=node->next ){
cout << node->value << " ";
}
cout << endl;
}
不要过分追求所谓“优雅”的写法
一般来说上面的三个函数一定程度上可以体现程序员编码的经验。
初学者会写出第一段代码,有一定经验的程序员一般会写第二种,而老手偏爱最后一种。 因为程序员会有一种“把代码写短”的倾向。而且多数程序员都认同用简洁的语句实现更优雅。
不过不过要注意,对于一个良好优化的编译器来说,这三者并不会有太大区别, 语句多不代表生成的机器指令多。语句少也不代表生成的机器指令就会比较少。 这纯粹是一种“美学”(是的,程序员需要提高自己的审美水平)上的倾向。
但从我的角度,我会认为最后一种写法对成熟的程序员来说太花哨(对大学生则刚刚好)。 因为工程上所谓好代码,最好是一眼看过去就明白他要表达意思,而不用太多的思考。 即:Keep It Simple Stupid(KISS)[1]。
所以你看,写代码时还需要考虑阅读者的水平。
在链表的最后插入,我们需要搜索到最后的节点,在其后面再插入:
void list_append( Node* head, int value ){
while( head->next ){
head = head->next;
}
head->next = create_node( value );
}
最前面的while循环帮我们找到最后一个节点,之后直接插入新节点。 可以看到我们使用之前编写的create_node函数,这也体现了代码复用。
我有代码可以复用吗?
在编写新函数或者新功能的时候,你总可以问问自己,我有写好的函数可以用吗?
别忘了测试你的代码,有了遍历打印的函数,我们可以很方便的进行测试。 也不要忘记测试边缘数据,本例中,你还应该测试一下只有头节点的情况。
销毁的过程和遍历非常相似,从头到尾走一遍,将每个指针释放即可。 这里需要注意的是,要预先记住next指针,否则指针释放之后无法再访问。 整个过程就断链了:
错误的销毁方式:
void list_destroy( Node* head ){
while( head ){
delete head; // 销毁之后,head就不能再使用了。
head = head->next; // 这里可能出现问题的。
}
}
正确的销毁方式:
void list_destroy( Node* head ){
while( head ){
Node* next = head->next; // 先记住next
delete head; // 此时才能销毁head
head = next; // 进一步
}
}
可以复用代码吗?
其实我们可以看出来,销毁和遍历在逻辑上是非常相似的,基于“不要复制粘贴”的原则,我们会自然地想要将这两者统一到一个函数下面,那么这样做可行吗?
这个回答只能说,行,也不行。
我们先看看如何要如何实现:
// func是一个函数指针
// 通过不同的回调函数提供函数的弹性
void for_each( Node* head, void (*func)(Node* node) ){
while(head){
Node* next = head->next;
func(head);
head = next;
}
}
// 回调函数,清空
void free_node( Node* node ){
delete node;
}
// 回调函数,打印
void print_node( Node* node ){
cout << node->value << " ";
}
// 具体实现
void list_destroy( Node* head ){
for_each( head, free_node );
}
void print_list( Node* head ){
for_each( head, print_node );
cout << endl;
}
这里的实现方式对大学生来说会有点复杂,对社会人则刚刚好。 要理解这里的实现,我们首先要理解函数指针和回调函数。
一般的函数封装了一部分行为,通过参数来提供定制性(弹性)。 举最常见的printf来说,函数封装了打印内容的行为。 但我们不会希望这个函数只能打印某个字符串。 为了让printf可以打印不同的内容。函数的设计者提供了一组参数来让我们实现自己的定制。 我们通过传递不同的参数数据,来控制printf的行为,这是printf的设计者在固定的框架下为不同行为提供的弹性。 通常通用的函数都需要提供一定的弹性,否则他的功能就太过单一,不好用了。
从这里我们可以看出来,函数有一定的固定性,即他的功能,也有一定的弹性(变化性),即传递给他参数的数据是可以定制的。
如果到这里还是比较好理解的话,那么我们进一步看,在上面的例子里,我们所需要的弹性已经不再是数据(例如"Hello World!")可以满足我们的了。
我们需要的弹性(或者说变化性)已经不再是简单的数据,而是某种行为。以上面的例子为例,我们需要的操作有两种,其一是销毁某个指针,其二是打印指针指向的某个成员。这都无法通过简单的数据来传递。因此我们需要把函数(行为)作为参数传递给函数。
一般我们管这种函数叫回调函数,回调函数是你交给其他人,由其他人来调用的函数。
在本例中,free_node和print_node就是这两个函数,我们通过传递不同的函数(行为)给for_each函数,使for_each函数能根据我们的参数对每个元素执行不同的操作。
这种操作在较为复杂的系统里可以说比比皆是,他可以很大程度上对系统进行解耦,有利于增加整个系统设计的弹性。
但代价是什么呢? 有三个代价:
- 代码的可读性降低了,你无法直观地一眼看出其执行逻辑。
- 架构的复杂性也上升了,对于跟踪和debug会带来一些负面影响。
- 性能会有所下降,函数指针无法被优化,一般会造成性能损失。
对于第三点,在复杂度较低的场景下也可以用宏来替代解决,但前两点是无法避免的。
因此我们说这里没有标准答案,如果你的系统复杂程度很高,团队的人员素质也很好,你更关注整体系统的弹性,对系统未来的扩展性非常重视,那么做好初始设计是非常有必要的。
反之如果这部分代码的应用范围很狭窄,没什么扩展性要求,那么用这种比较复杂的设计就是完全不必要的(过度设计)。
与大家在学校解题不一样的是,工程上常常没有正确答案,一切都取决于你如何取舍[2]。
插入和删除元素
插入元素
如果我们获得某个元素的指针node,我们可以很方便在其后面执行插入的操作:
对应的代码:
void insert_after( Node* node, int value ){
Node* new_node = create_node(value);
new_node->next = node->next;
node->next = new_node;
}
这里的三条代码正好对应上面的三个图,非常清楚。要注意的是这里的次序非常重要,如果你这样写就错了:
void insert_after( Node* node, int value ){
Node* new_node = create_node(value);
node->next = new_node; // 这句已经把node->next丢了
new_node->next = node->next; //此时node->next = new_node
}
如果你不是很理解,自己画图体会一下。
删除节点
如果知道某个节点,删除其后面的节点也是很简单的:
可以看出过程几乎是插入的逆操作:
void delete_after( Node* node ){
Node* next = node->next;
node->next = next->next;
delete next;
}
这里同样要注意次序,就不赘述了。
前插和删除当前节点
对单链表来说,只知道某个节点是无法执行前插操作的,因为这里涉及到前向节点。 如下图: 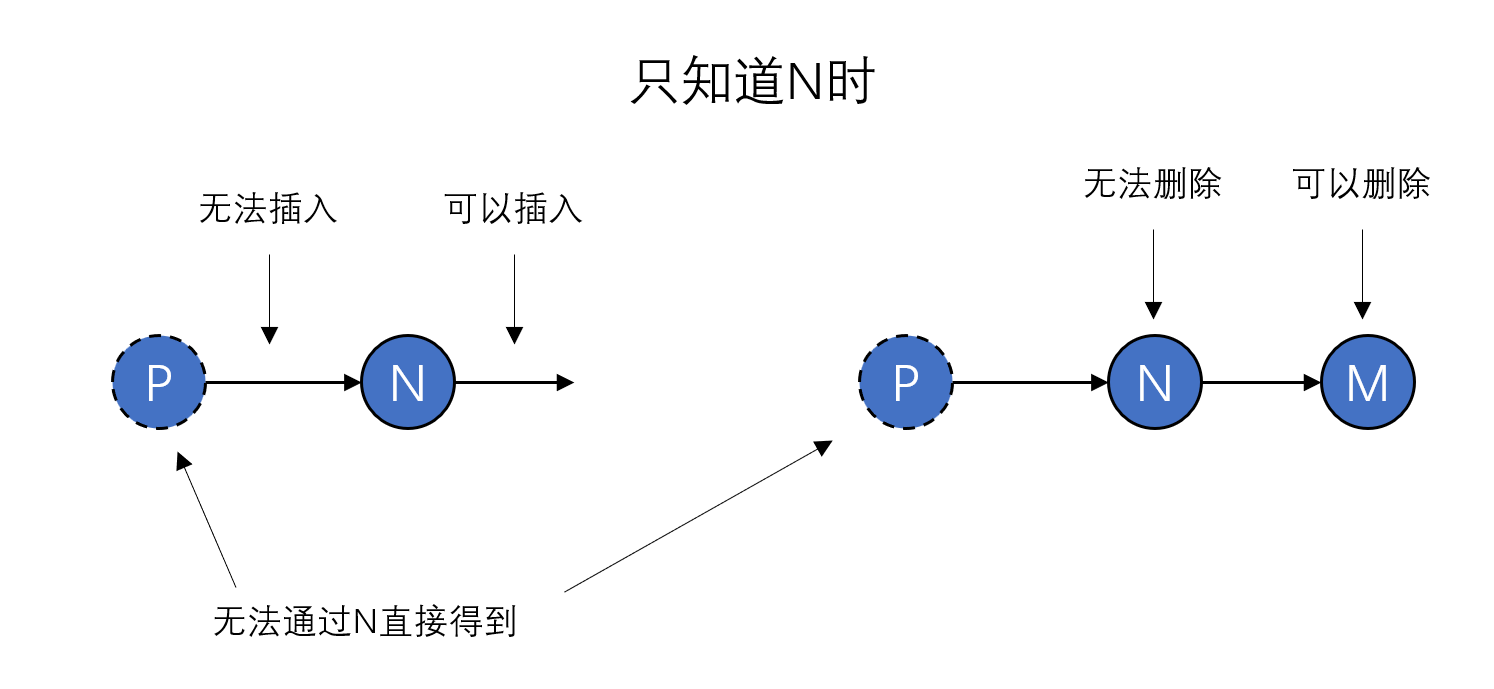 这里要在
这里要在N的前面插入节点,需要修改P的next指针,但从N无法直接得到P,因此无法完成插入的操作。 与之相类似的,只知道N,也是无法删除该节点的。因为同样也需要修改P的next指针。
因此,要执行这两个操作,必须获取节点N的前向节点P。对于单链表,只能从头节点向后搜索。 所以我们需要一个额外的头节点指针来完成这两个操作:
Node* find_prev( Node* head, Node* node ){
while( head->next != node || head != nullptr ){
head = head->next;
}
return head;
}
void insert_before( Node* head, Node* node, int value ){
Node* prev = find_prev(head, node);
assert(prev!=nullptr);
insert_after(prev, value);
}
void delete_node( Node* head, Node* node ){
Node* prev = find_prev(head, node);
assert(prev!=nullptr);
delete_after(prev);
}
这个代码很容易理解,请自行阅读。
要再次强调的是,这里还是充分复用了前面的代码,从而使逻辑变得更加清晰和简单。 这带来的另一个优势是,如果对前面写的insert_after和delete_after进行了充分测试, 可以保证这些函数是正确的,那么这里一旦出现问题,只可能是出现在find_prev函数里。 这会使定位问题和debug变得简单许多。
头节点
实际上上一节最后的两个函数是不安全的——因为边界并没有被很好的测试。 这个边界就是头节点。 当我们需要在头节点前面插入一个元素,或者删除头节点时,因为不存在prev节点,就会导致错误:
insert_before(head, head, 0); // 错误,head没有prev节点!
所以你实际上需要这么样写:
void insert_before( Node* head, Node* node, int value ){
if( node == head ){
Node* new_node = create_node(value);
new_node->next =node;
return;
}
Node* prev = find_prev(head, node);
assert(prev!=nullptr);
insert_after(prev, value);
}
void delete_node( Node* head, Node* node ){
if( node == head ){
delete node;
return;
}
Node* prev = find_prev(head, node);
assert(prev!=nullptr);
delete_after(prev);
}
然而这实际上也会带来问题,例如我们在前面插入一个值:
insert_before(head, head, 0);
print_list(head);
你会得到
1 2 6 3 5
而不是从0开始(当然你也会得到一个内存泄漏)。delete_node则更加糟糕,你可能触发非法内存访问。
究其原因很简单,我们一直把head和整个链表等同起来看待。head就是链表,链表就是head,还记得吗?但当我们往head前面插入元素时,链表的头节点就不再是原来的head了!你还用原来的head去操作,必然带来问题: 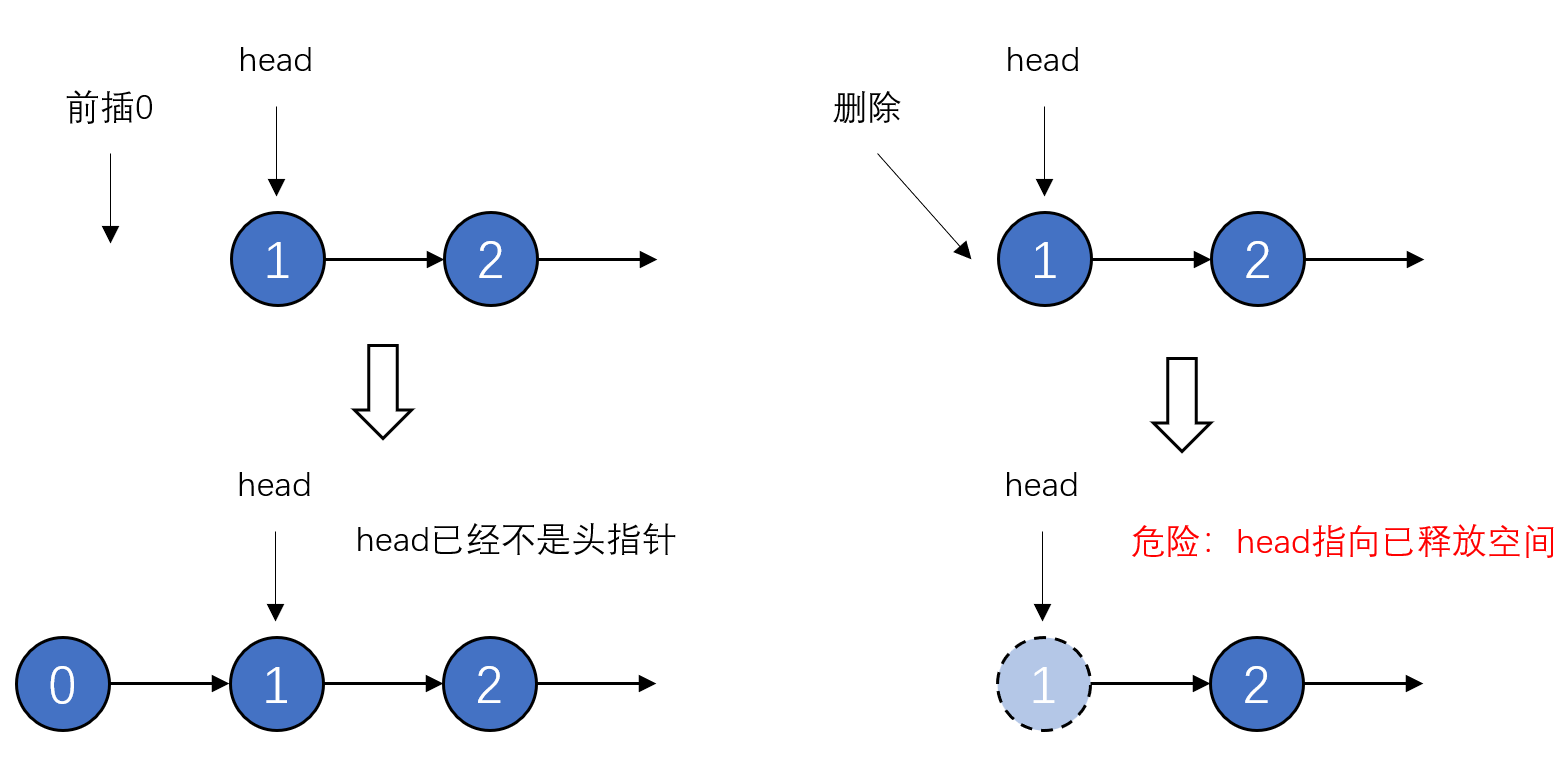
所以,在头节点发生变动时,链表的状态就不再是原来的状态了。 如何解决?你们可能会在很多书上看到类似的写法:
Node* insert_before( Node* head, Node* node, int value ){
if( node == head ){
Node* new_node = create_node(value);
new_node->next =node;
return new_node;
}
Node* prev = find_prev(head, node);
assert(prev!=nullptr);
insert_after(prev, value);
return head;
}
Node* delete_node( Node* head, Node* node ){
if( node == head ){
head = head->next;
delete node;
return head;
}
Node* prev = find_prev(head, node);
assert(prev!=nullptr);
delete_after(prev);
return head;
}
可能改变头节点的情况下,要求函数必须返回head,以便外部更新链表头指针:
head = insert_before(head, head, 0);
print_list(head);
head = delete_node(head, head);
print_list(head);
这种处理不能说大错特错,只能说和正确毫不沾边。 原因很简单,你可以要求使用这些函数的用户更新head, 但你无法要求所有拿到head指针的用户都更新这个指针:
Node* head_to_others = head; // 将head传递给其他人使用
head = delete_node(head, head);
print_list(head); // 可以,没问题,head正确更新。
print_list(head_to_others); // 我的头指针呢,刚刚还在这里,这么大的一个!
除非你有办法更新所有拿到head指针的用户,否则这种方式就完全没用。
明白了问题的原因,我们就很容易解决问题了:只需要保证head永远不会发生变化即可!。 要做到这点,我们可以让head变成一个废节点,所有有效节点都从head->next开始。
既然head已经躺平,我们就没有理由操作他,插入元素一定在他后面,删除元素也删不到他身上。 拿到这个head的用户就可以放心地使用他了。
这样的话,代码就需要一些修改:
Node* create_list(){ // 不在需要赋值,头节点的值没有用处
return create_node(0);
}
以下这5个函数不需要修改:
void list_append( Node* head, int value ); // 不需要修改,都是在尾部插入元素
void list_destroy( Node* head ); // 同样不需要修改,头节点也需要释放
void insert_after( Node* node, int value ); // 在节点后插入,对头节点同样适用
void delete_after( Node* node ); // 删除节点后的元素,对头节点同样适用
Node* find_prev( Node* head, Node* node ); //同样不需要修改,思考下,为什么
遍历链表的方式发生变化,需要从head->next开始遍历,所以以下函数需要发生变化:
void print_list( Node* head ){
head = head->next;
while(head){
cout << head->value << " ";
head = head->next;
}
cout << endl;
}
对于insert_before和delete_node函数来说,因为不需要再考虑头节点问题。 就可以恢复到一开始的状态了(思考下,为什么):
void insert_before( Node* head, Node* node, int value ){
Node* prev = find_prev(head, node);
assert(prev!=nullptr);
insert_after(prev, value);
}
void delete_node( Node* head, Node* node ){
Node* prev = find_prev(head, node);
assert(prev!=nullptr);
delete_after(prev);
}
我们把这种头节点是废节点的链表称为带头节点的链表。以后遇到这种术语,就要注意他的头节点是不用的。 现实中所有应用的链表基本上都是带头节点的,原因很简单,基于我上面说过的理由:
原因很简单,你可以要求使用这些函数的用户更新
head, 但你无法要求所有拿到head指针的用户都更新这个指针:
不带头节点的链表的应用范围极其狭窄。
还有其他理由吗?
有!
如果你仔细对比前后两组insert_before和delete_node函数,你应该能感觉出两者的代码给你的感受完全不同。
一个优秀的程序员,必然更加倾向于后一种解决方案,即便这种方案会浪费掉一个空间。
这就是我们说的更优雅的实现(good tastes)。
你可以看这个视频感受一下什么叫编码的tastes: https://www.bilibili.com/video/BV1PZ4y1s7EW?p=2 从14:19分开始
搜索
包括两种搜索方式,搜索第n号元素和搜索某个值的元素。 复习一下,对于顺序表,这两者的时间复杂度各是多少? 那么对于链表,你觉得时间复杂度又是多少呢?
搜索是比较简单的操作,请自行编写代码尝试并到OJ上验证你的代码。
链表的其他形式
单链表的最大问题在于只能向前,不能向后。这带来的问题就是从任意一个节点开始,都只能访问到他后面的元素。 解决这一问题有两种方案:循环链表和双向链表(以及两者结合,双向循环链表)。
循环链表
传统单链表的最后一个next指针是空指针,通过他来告诉我们链表结束了。如果将这个next再指向链表的头节点head,就构成循环链表,你应该很容易理解这种造型:
这里用黑色表示不使用的头节点。
这种结构带来的优势是,从任意一个节点出发,都可以遍历整个链表。 缺点也很明显,你无法区分哪个是头节点,哪个不是,除非你为头节点设置专门的一个标志位。因此在操作时需要小心。
在循环链表的状态下,我们前插节点和删除节点,就不需要头节点指针了。我们可以直接从自己开始,找到自己的前向节点。就像你不能扭头,那么要怎么看到后面的东西呢?只需要绕地球跑一圈回来就行了。
思考一下
- 初始化循环链表的表头时,
next应该指向谁? - 要如何遍历循环链表,才能保证不进入死循环。
- 尝试写一下前插的函数和删除当前节点的函数。
- 前插删除当前节点的函数,复杂度是多少,与单链表有什么不同?
- 如果头节点没有标志位标识他是头节点(即你无法区分头节点和普通节点),那么可以从任意节点出发,在循环链表里寻找等于某个值的节点吗?
- 把元素插入链表尾部,在链表和循环链表上复杂度一样吗?
- 循环链表带来哪些额外的开销?
双向链表
另一种解决方案比较粗暴直接,既然我们需要前向节点,那么我们直接记录每个节点的前向节点指针就可以了,这种链表被称为双向链表:
struct DualNode{
int value = 0;
DualNode* prev{nullptr};
DualNode* next{nullptr};
};
此时的前插就很容易写了:
void insert_before( DualNode* node, int value ){
DualNode* prev = node->prev;
DualNode* new_node = create_node( value );
prev->next = new_node;
new_node->prev = prev;
new_node->next = node;
node->prev = prev;
}
或者,如果你不想使用中间变量:
void insert_before( DualNode* node, int value ){
DualNode* new_node = create_node( value );
new_node->prev = node->prev;
node->prev->next = new_node;
new_node->next = node;
node->prev = new_node;
}
请你自己写一下删除的代码,如果对编码没有自信,记得先用纸和笔画一下,再写代码。
思考一下
- 双向链表在后方插入的代码要怎么写,有边界问题吗?
- 已知节点
node,单链表、循环链表、双向链表在删除和前插的算法复杂度有区别吗? - 已知节点
node,单链表、循环链表、双向链表在后插和删除后向节点的算法复杂度有区别吗? - 单链表,循环链表和双向链表在尾部插入和头部插入节点的算法复杂度有区别吗?
- 你认为什么情况下,我们可以实现向头部插入的复杂度与尾部插入的复杂度相同?
双向循环链表
单纯的双向链表在实际工作中也很少用,真正常用的链表是双向循环链表。
把双向和循环加在一起,就得到了双向循环链表:
注意下这里头节点和尾节点的两个指向。头节点的prev指向尾节点,尾节点的next指向头节点。 这两prev和next都构成两个环状结构,但遍历的方向不同。
双向循环链表的代码请大家自行编写,但这里还是要问几个问题:
思考一下
- 当双向循环链表里没有元素时,请问,头节点(注意此时头节点依然存在)的
prev和next分别指向谁? - 请你写出在双向循环链表的尾部插入元素的代码,请问代码复杂度是多少?
- 遍历双向循环链表时,应该以什么条件作为结束的标志。
- 如果我要取双向循环链表的中间节点,请问,每个元素至少需要遍历几次?
总结
我们上面讨论了那么多种链表,当你对链表的操作熟练之后,就会发现他和顺序表的不同。 或者换句话说,他几乎就是顺序表的反面:
| 性质 | 顺序表 | 链表 |
|---|---|---|
| 随机访问 | 可以 | 不行 |
| 内存分配 | 需要预留 | 按需分配 |
| 增删便利性 | 不方便 | 方便 |
| 内存额外开销 | 少 | 较多 |
回顾下我们第一节课的第一个坦克大战的例子,我们来更新下需求,你再想想该如何设计?
- 地图的尺寸不固定,可变。
- 地图上的地方坦克依然是最多6辆。
- 每个坦克的子弹随机发出,随机消失。
- 地图上可能随机出现道具,当你没吃到道具时,他会在30s之后消失。
- 子弹击中坦克或者场景,都会触发特效,特效有一定持续时间,到时候自动消失。
再回顾下第二个MC的例子,现在你会如何设计MC的地图更新策略?用什么数据结构来实现?
写在最后
对初学者来说,链表是极其重要的一步。 这一步从相对静态的编码模式转入相对动态的编码模式,同时要求你对指针的运用非常熟练。 因此请安心在这里刷完所有的题目再向前启程。
这里还有一些额外的阅读材料可能可以提供给你更多的帮助:
- Linux内核链表的实现,这是一个非常经典的链表实现,当你搞懂之后,你一定会发出,我去,还能这样的感慨。
- C++的array容器,C++的vector容器和C++STL的链表容器,我们需要知道轮子是怎么造出来的,但不一定需要造轮子。你还可以体会C++和C在同一个问题下的不同解决思路。
- Java的Vector类,Java的Array数组和Java的LinkedList,体会下Java和C++的不同设计思路。