第一章 绪论
第一章 绪论
引子
在讲述引入数据结构是什么之前,我们先讲两个三个例子:
第一个例子
第一个例子是大家的童年回忆:

坦克大作战
你们现在已经是专业的程序员了,应该有一些基本的职业病。比如,看到游戏的时候,就要问问自己,要如何实现。 那么我们来想想,如果你是坦克大作战的程序员,你要如何组织数据。
我们可以简单分析一下。 坦克大作战有很多关卡,但这些关卡和后面的超级马里奥等游戏不同,它的场景尺寸是固定的。 因此我们简单用二维数组来存放即可,数组的值用来该块地图的属性,例如空白、砖块、草地、铁块、水等。(PS:你觉得数组的尺寸应该是多少?) 坦克破坏地形时,我们直接修改对应的二维数组即可,每一轮绘制时,我们根据数组的值来将合适的块绘制到指定的区域。
坦克我们可以用一个结构体来表示,包括我方坦克和敌方坦克。那么我们需要几个坦克变量呢? 我方坦克的数量上限是2个,场景中敌方坦克的数目是有上限的,不能超过6辆。因此我们只需要两个坦克的数组即可。
我们可以简单设计这样一个数据的组织形式:
struct TANK{
int type;
bool is_dead;
int x,y;
int direction;
int level;
//....
};
struct BLOCK{
int type;
//...
}
BLOCK scene[WIDTH][HEIGHT];
TANK player[2];
TANK enemy[6];
//....
这三个数组足够我们表示一个场景中的除去子弹之外的所有内容(不包括特效的话) 因为他们都是固定的,可以预计的东西。我们用数组来存放非常合理。
但在子弹这里就行不通了。子弹是会随机产生,随机消失的,有很大的不确定性,数量无法精确预测(虽然可以确定一个不太精确的上限)。
第二个例子
第二个例子是现在的传奇:
Minecraft拥有近乎无限大的地图,同时地图还有第三个维度,地图上的生物也是完全随机的。 如果是你,要如何应对这样的需求?
MC的设计不是一两句话能说得清楚的,但我们也可以简单分析一下:
第一个比较大的问题是MC巨大的地图。显然我们是无法将他们全部塞进内存里的。 我们可以想到的方法是按需加载:
只加载角色周围一定区域的地图内容。 随着角色移动,我们随时更新这部分数据。这样保证加载到内存里的数据始终是有限的。
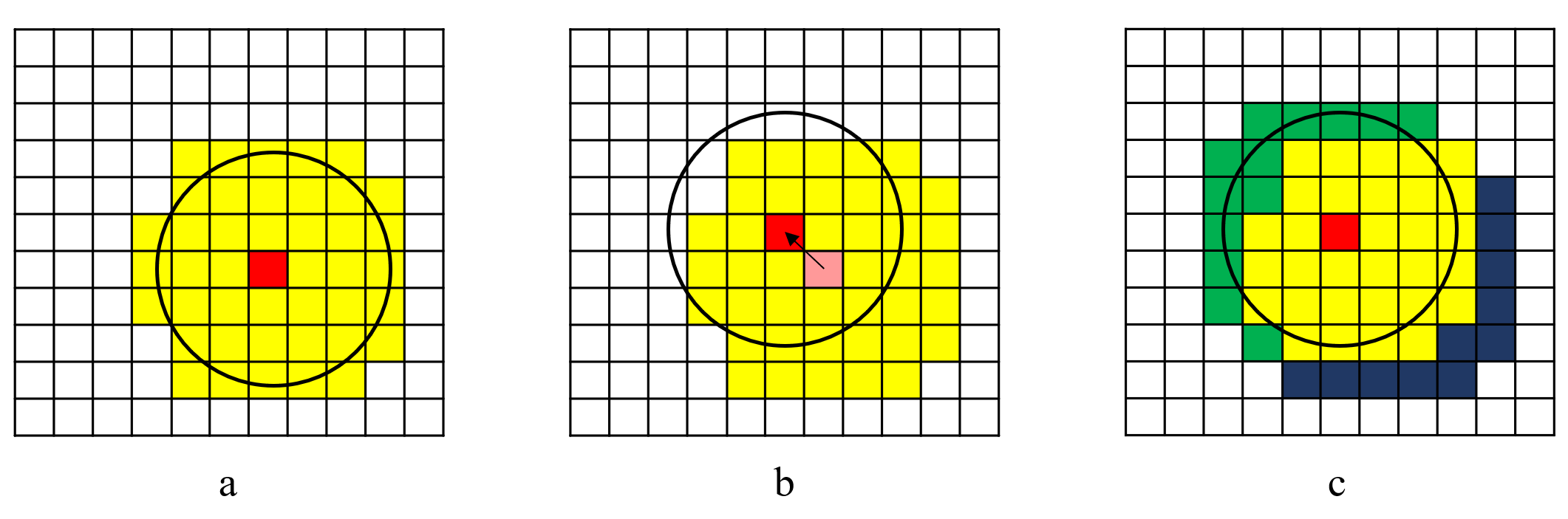
上图里,图a展示我们加载的范围,当角色发生了移动(图b)时,角色移动到了新的区域,需要更新角色的范围并加载对应的区域。
我们甚至可以采用增量加载的方式来处理这一过程(图c),只卸载掉已经不在范围的块(黑蓝色)。 已经在原来范围中的块就不需要重复进行卸载和加载了(黄色),我们保留它们。 而原来不在区域中的块,我们就需要从磁盘里加载出来了(绿色)。
这样可以大幅度削减我们每次加载的数量,只要这一过程足够快,因为远处的场景通常对视觉的贡献很小,我们甚至可以无缝地在地图里漫游,让玩家完全感受不到加载的发生。
在这个例子里,数据块的组织就是一个比较核心的问题。我们可以看到,数据块不是方方正正的,用数组来表示就很不合适。 更麻烦的是,这里的块要进行频繁的卸载和加载,而且没有明显的规律,这更增添了处理的难度。
从这两个例子我们可以看出,随着逻辑复杂度的增加,你们掌握的“基础”的数据组织方式——数组,已经不能满足我们的要求了。 我们需要更为强大的数据组织工具来面对更复杂的软件需求,这是数据结构这门课希望大家掌握的第一个能力。
第三个例子
你们打游戏的时候,一定希望延迟越低越好。互联网的连接依赖于路由器传递数据。你可以把路由器想象成一个个的快递站。 从你家的网关到游戏服务器之间一般会有多个路由器,路由器和路由器之间彼此相连,因此从你家的网关到游戏服务器之间存在不止一条的路径:

如上图,假设你家的网关是A,游戏服务器是F。中间的BCDE是途径的路由器。节点和节点之间连线上的数字表示本条路径的时延。
既然我们希望延迟越低越好,问题就转变为:如何在这个网络上,求点A到点F的时延总和最小的路径。 这一问题称为图的最短路径算法[1]。
在这个问题里,我们可以把问题抽象成如下描述:
在一个带权(路径上的值称为权)图中,如何计算两点间的最短路径。显然这涉及到两个问题:
- 如何在计算机里描述一个带权图
- 如何根据这个描述来计算最短路径
在这个例子里,我们不仅涉及如何在计算机中组织(描述)这个现实中存在的模型。而且涉及如何在这个模型上执行一定的算法来帮我们解决问题。
这是数据结构这门课希望大家掌握的第二个能力:通过数据组织形式和在其之上的算法,帮我们解决现实的问题。
什么是数据结构
实际上数据结构并没有一个明确的定义。
《算法导论》[2]上认为数据结构是数学上集合在计算机科学上的体现,也即如何处理动态集合元素的技术。 《数据结构(C语言版)》[3]里认为数据结构是研究非数值计算程序设计中的操作对象,以及这些对象间的关系和操作的学科。 Clifford A.Shaffer的《数据结构与算法分析》[4]中,认为数据结构是ADT(Abstrct Data Type,抽象数据类型)的物理实现。 维基百科上的叙述可能更符合我们的习惯看法:数据结构是计算机中存储、组织数据的方式[5]。 浙大版《数据结构》[6]对数据结构的定义是:数据对象在计算机中的组织方式,以及关联于这些数据对象的操作(算法)。
从这些定义中我们可以看出:
- 数据结构主要解决的是数据的组织和存储的技术。
- 数据结构解决的问题还包括对这些数据的操作(增删或者查找)。
- 数据结构处理的是动态的数据。
- 数据结构与算法是紧密联系的。
从前面的两个例子我们也可以看出,对于第一个例子这种数据固定,不会有太大变化的场景,用C语言里学到的那些内容足够应付,顶多用个数组。 但对第二个例子而言,如果数据的动态变化很频繁,就需要引入更高层次的数据结构才能解决。
因此数据结构首先是帮我们解决动态数据如何组织的技术。这种组织不仅包括数据应该如何存放,也包括增加、删、查找等基本操作。
其次从第三个例子上可以看出,这些数据组织的方式,也可以帮我们更好的解决现实问题。事实上我们会发现,数据结构和算法经常是相辅相成的。 要应用某种算法,我们必须掌握对应的数据结构才可以。例如,你要学会深度优先搜索,就要先掌握栈。要学会广度优先搜索,就要先掌握队列。
数据结构的类型
《数据结构(C语言版)》[3:1]里从逻辑结构和物理存储两个维度对数据结构进行划分。前者是各个数据结构的内在逻辑。后者则是实现的细节。
从逻辑维度区分
可以简单分为两大类,线性数据结构和非线性数据结构,当然非线性数据结构的范围很广。
下面这张图是我们会接触到的数据结构的大致分类,可以使大家对学习内容有一个直观的感受。其中灰色的部分不在大纲要求范围以内,根据授课时间决定是否讲。
如果按我们授课的内容来看,我们主要围绕线性的数据结构、树和图这三者展开。再加上最后的排序。这三类数据结构的区别,可以看下图:
线性结构的每个节点都有一个前驱一个后续。 树的每个节点只有一个父节点,但可以有多个子节点。 图则没有明显的从属关系,任意一个节点都可以跟其他节点相连。
从物理存储结构区分
从物理存储的角度去区分是从更细节的实现角度去看的。 上图中,我们用箭头表示节点的后续,可能会给大家一个错误的暗示,即节点和节点之间是以指针相互关联的。
但其实不然,箭头只表示一种逻辑关系,并不必然需要用指针来实现。
以线性数据结构为例,如果我们用连续的内存来存放每个数据(即数组,或者顺序表)。那么数组下标天然就体现了他们之间的顺序关系。此时数据在物理空间上连续存放,因此我们可以快速地访问第N号元素(直接用下标即可),但显然插入或删除一个数据则麻烦的多。这种存储方式我们称为顺序存储。
如果我们在每个节点中都设置next指针域来指向下一个节点,此时数据就可以不在物理空间上连续。因为节点和节点之间是依次相连,形成一条链条,因此称为链式存储。这种节点添加和删除节点都只影响局部,代价比较小。但显然你不能随便访问任意一个节点,每次都需要从头开始搜索。
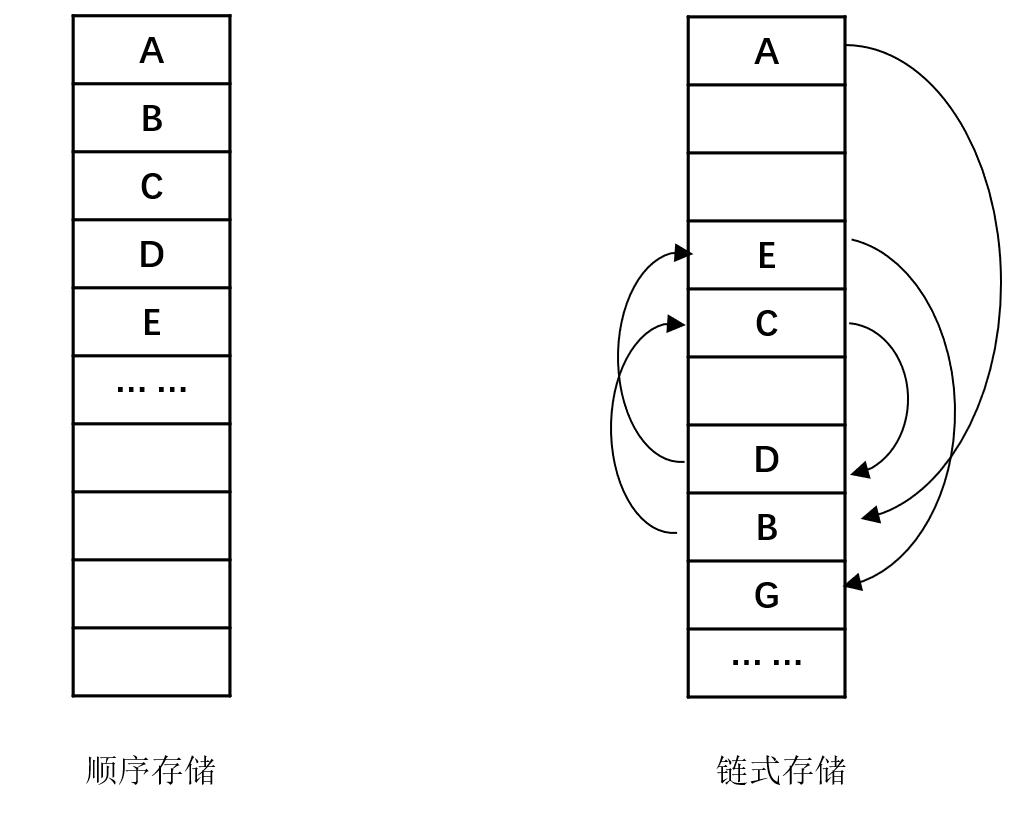
这两种存储方式的区别我们在第一章的线性表里就会遇到并详细讨论。
另一种误区是顺序存储的方式只能在线性结构里使用,因为顺序存储缺乏像链式存储的弹性,似乎很难表现一个节点对应多个节点的情况。其实不然,以树状结构中的堆为例,通过精心的设计,我们也可以用顺序存储的方式来表达复杂的结构:
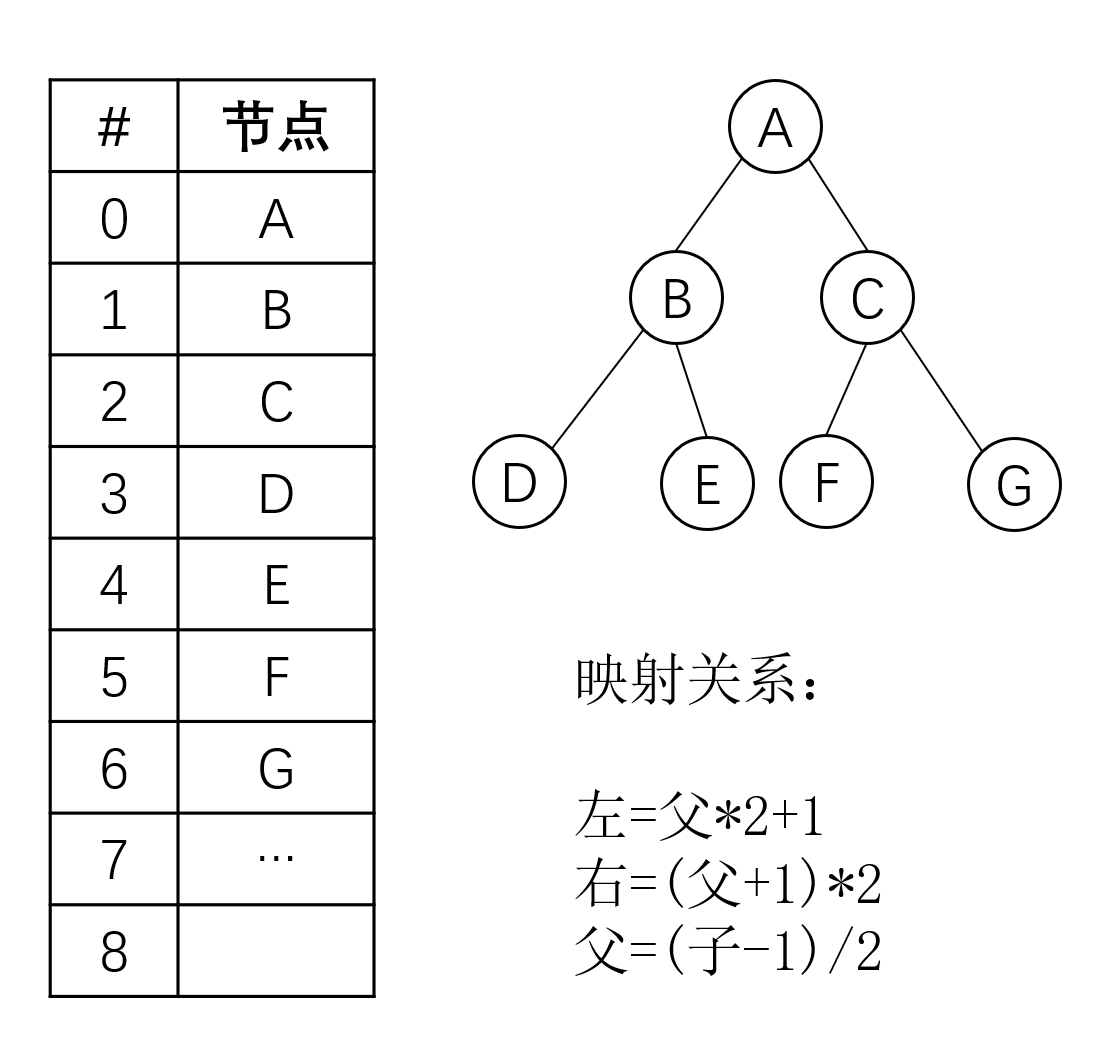
在这个映射关系里,任意一个节点都可以通过简单的计算,得到其父节点或者任意一个子节点的下标。因此虽然我们存储的结构是紧凑的顺序存储方式,但从逻辑结构上他其实是一棵二叉树。
抽象数据类型
教材上的抽象数据类型大家可以理解成伪代码,使用面向对象的方式来编写。 本讲义中不会使用抽象数据类型来描述代码,而是使用真实能运行的代码来展示。 但大家一定要有概念,书本上的代码是无法直接运行的。
抽象数据类型的严格定义是数学模型和该模型上的一组操作,从这个定义上我们可以看出,最适合表示抽象数据类型的显然是面向对象的方式:数据集合就对应面向对象的属性(成员变量);操作就对应面向对象的方法(成员变量)。
因此本讲义中会尽量采用面向对象的方法来描述抽象数据类型,对面向对象还有疑惑的同学请翻看前面的预备知识:C++的最小子集章节。
算法和算法复杂度
算法的定义
前面已经提到,数据结构上的算法也是本课程重要的学习重点之一。算法是我们用来解决问题的套路。《算法导论》[3:2]中对算法的定义是:一个计算过程,负责把输入转换成输出。
一个算法通常需要多个步骤,有些步骤还可能要反复执行,但这些步骤必须是有限步(或者说,可停机)。我们看一个典型的算法:
int gcd( int m, int n ){
if( n>m ){
swap(m,n);
}
while( n != 0 ){
int r = m%n;
m = n;
n = r;
}
return m;
}
这是求两数最大公约数的辗转相除法,也称欧几里得法。
这个函数有输入(m和n),有输出(m和n的最大公约数),那么步骤是否可以在有限步内结束呢? 仔细分析我们可以发现,由于m在整个过程中不断除n求余数,这个余数一定一定是不断缩小的。由于m和n都是有限大的整数,因此这个步骤必然在有限步内结束。所以我们可以说,这是一个算法。
要注意的是,我们研究算法当然是为了在计算机上跑,但算法未必需要以计算机语言的方式来表达。欧几里得的时代绝对不可能有计算机,但辗转相除法依然被认为是算法,我们用语言也可以进行描述:
1. 取m,n中较大的那个数,不妨设较大数为m,令m/n,得到余数r。
2. 如果余数为0,那么两者最大公约数就是n(较小的那个)。
3. 如果余数不为0,就对n,r重复上面的过程
上面这个算法语言描述,显然是无法在计算机上运行的。但他依然满足有限步内可以结束并得到输出这个条件,所以我们依然认为他是算法。
从这个算法里,我们还能看出一些有意思的点,假如每次给的m和n是相同的数字,我们可以预计,这个算法每次都会得到相同的结果。实际上它的每个步骤,都不会有任何变化,完全相同[7]。
一般来说,人们认为算法需要有以下五个特征:
- 有穷性,即算法需要在有限步内结束。
- 确定性,即每个步骤之后应该如何执行,需要明确定义,不可以有二义性。
- 可行性,算法步骤需要能被计算机执行(例如,取最大整数,就不是可以被执行的步骤)。
- 输入,可以没有输入,但也可以有多个输入
- 输出,算法至少要有一个输出,否则算法就没有意义。值得注意的是,这里的输出是广义上的,并不一定要是函数的返回值才叫输出。如果算法的执行过程导致某个对象的状态发生了变化,那也是输出。
算法的评价-时间复杂度
我们看另一段代码:
int gcd_slow( int m, int n ){
int r = 1;
for( int i=2; i<=n && i <=m; ++i ){
if(n%i == 0 && m%i == 0){
r = i;
}
}
return r;
}
这段代码用最传统笨的方法求最大公约数。从1开始,测试每个数字,直到等于m,n的某个数字为止。显然这也是一个算法。那么对比这两个算法,哪个算法更好呢?要如何对比两个算法呢?
显然我们希望算法越快越好,但你们一定能想到,算法的速度跟我们计算的规模是正相关的。举例来说,如果我们用一个算法计算两个10位数的最大公约数,另一个算法求两个2位数的最大公约数。显然对前一个算法是不公平的。此外同一个算法,在你的电脑上跑的速度和在你同学的电脑上跑的速度也可能有差异。所以我们需要一个归一化的、“公平”的评判标准,来对比两个算法。
一般地,人们用核心代码的执行次数和规模的函数来指代一个算法在时间上的效率,这一衡量方式被称为渐进复杂度,简称复杂度,所谓渐进是指随着规模n的增长,算法执行时间的增长率会越来越接近某个n的函数的增长率。
举例来说,对上面的算法gcd_slow,随着m和n的增长,我们可以预见,核心代码即第4、5行的代码也会同步增长到m,n的最小值,那么我们就说他的时间复杂度是的[8]。我们可以假设m和n很接近,那么这里可以简单记为。
而对于前面的算法gcd,可以证明其算法复杂度是的,对比这两个复杂度,我们可以得出结论,gcd相比gcd_slow,在运算效率上更高。
复杂度分析
一般我们更关心的是复杂度的量级,诚然的算法比快,但这种速度优势在的算法面前不值一提。所以一般我们会忽略系数,直接用其幂次来表示复杂度,也就是说,我们认为。此外跟级数展开很类似的,我们更关心高次项,后面的低次项对整体增长率的贡献基本可以忽略,也就是说,我们认为。以此类推,显然:有。
这种简化有助于我们抓住算法的本质。
一般来说,算法复杂度从小到大有这么几个级别:
- ,常数级。例如,从数组中获取第
n号元素。 - ,对数级。例如前面的
gcd,或者二分搜索,通常不写对数的底数。 - ,前面的
gcd_slow。 - ,简单理解成将执行
n回。 - ,你们常用的双层循环。
- ,多项式级别。
- ,注意和上面的区分,指数级。
- ,这个级别基本无法计算。
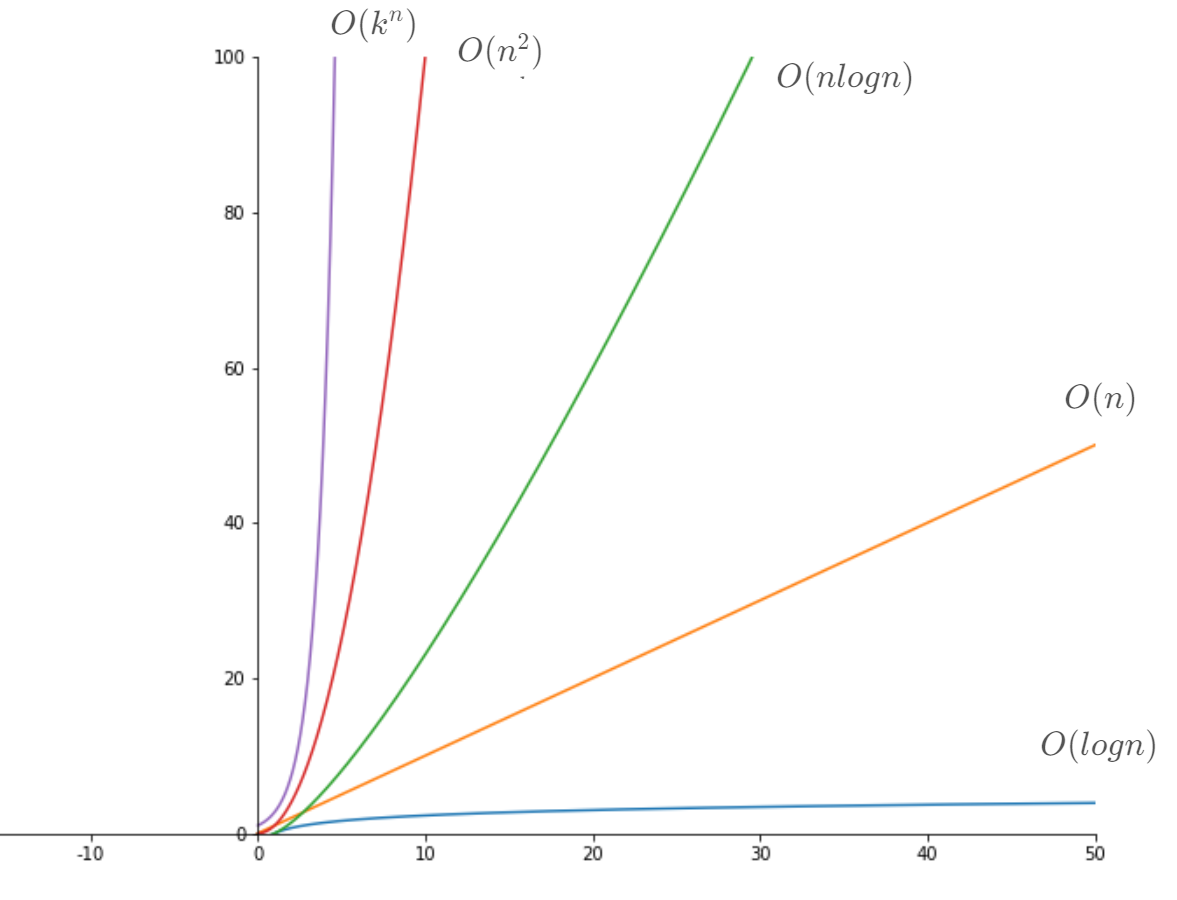
有些场合下,算法的速度不仅仅依赖于问题的规模,也和输入数据如何排列有关系,在排序算法中这点非常明显。某些算法可能非常适合处理某些特殊的数据,但对另一些数据则表现很差;而某些算法可能正好相反。因此我们有时候还需要分析最好时间复杂度和最坏时间复杂度。最好时间复杂度是算法可能达到的最好的复杂度,通常此时的输入都非常特殊。同理,在某些特殊的数据下,算法会给出最坏的表现,我们称此时的复杂度为最坏时间复杂度。一般情况下人们更关心的是最坏的情况。很多时候可以把最坏时间复杂度等同于时间复杂度。
空间复杂度
理解了时间复杂度,我们就很容易理解空间复杂度。
很多算法在执行的时候,需要额外的空间存储中间过程。显然这一空间也跟规模相关,所以我们可以模仿定义时间复杂度的方式来定义算法的空间复杂度。空间复杂度也有着跟时间复杂度一样的性质。
值得注意的是,很多时候时间复杂度和空间复杂度是无法两全的。也就是说你必须在选择跑得慢一些,但更省空间(用时间换空间)和占用更多空间,但跑得更快(用空间换时间)两者之间进行二选一。在计算机存储器已经不再捉襟见肘的现在,人们往往回选择后者,即更看重时间复杂度。
不要以为这种算法只能在学术圈里讨论,如果你对网络协议有所了解的话,就知道开放最短路径优先协议(ospf)正是使用最短路径算法来计算路由的。 ↩︎
Thomas,H.Cormen,Charles,E.Leiserson,Ronald,L.Rivest,Clifford,Stein,殷建平,徐云,王刚,刘晓光,苏明,邹恒明,王宏志. 算法导论(原书第3版)[M]. 机械工业出版社, 2013(10):1. ↩︎
克利福德A.谢弗, C.A.). 数据结构与算法分析:C++版[M]. 电子工业出版社, 2010. ↩︎
中文维基百科. 数据结构[EB/OL]. https://zh.wikipedia.org/wiki/数据结构, 2022.6.17. ↩︎
陈越 主编, 何钦铭,徐镜春 等编著. 数据结构[M]. 高等教育出版社, 2016. ↩︎
需要注意的是,并不是所有算法都满足这个条件,但所有算法在执行步骤上,都应该明确地知道下一步需要如何执行,而不是你既可以...也可以....。 ↩︎
这里的定义只是一个很简单的描述,并不严格,时间复杂度有很严格的定义和计算方式。但本课程并不是算法课,这部分内容请留待算法课来深入。 ↩︎