栈和队列 - 概念与实现
栈和队列 - 概念与实现
栈
栈的概念
栈只能在一端添加或者删除。很容易想象得到,如果你要拿到最下面的元素, 就必须把上面的元素都拿掉才行。 现实中我们很容易找出这样的例子。无论是叠放的碗或者盘子,还是放入行李箱的衣物。 最先放进去的都会被压到最下面。当你拿出来的时候,最先放进去的一定回到最后才能被拿出来。 
我们把这种情况称为:后进先出(LIFO,Last In First Out),或者先进后出(FILO,First In Last Out)。
后进先出是栈的特点。
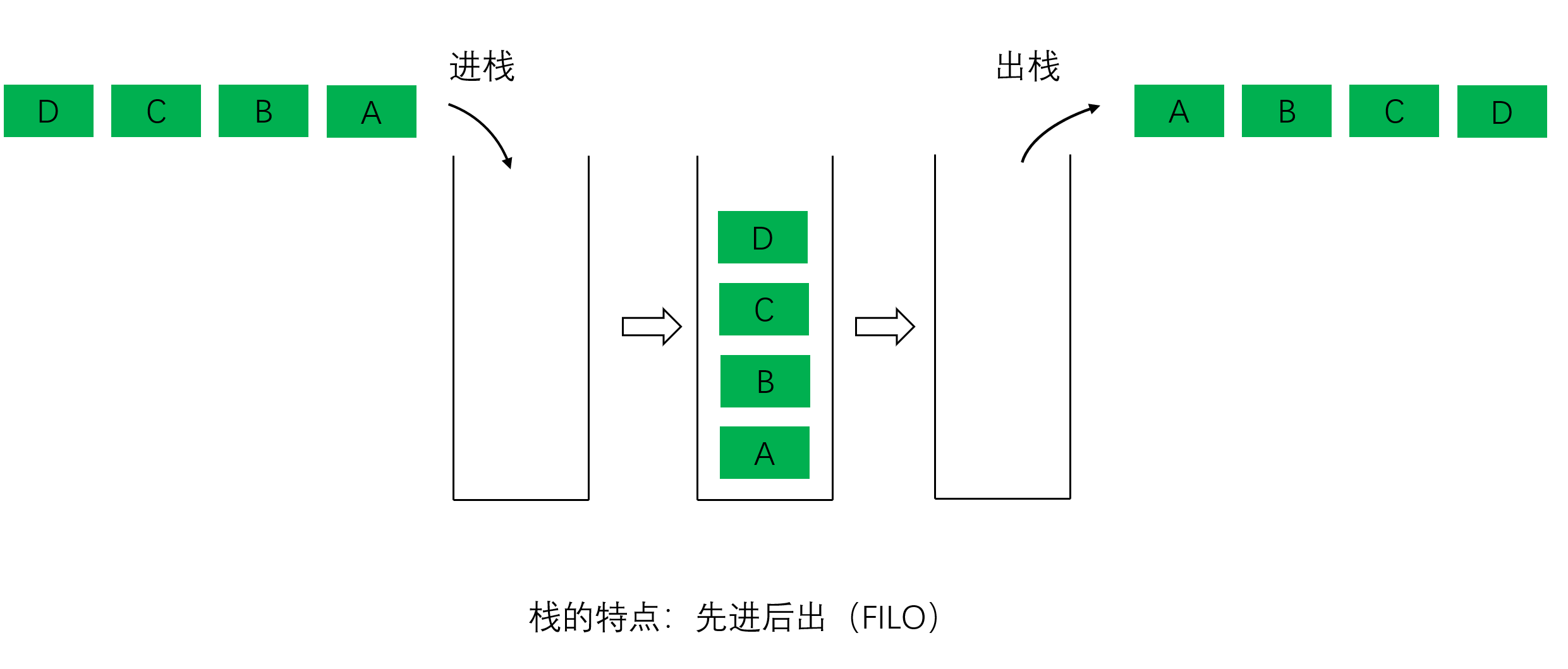
栈的操作
对于栈,只有两个非常简单的操作,即入栈和出栈。数据结构上我们一般用push(压栈)和pop(弹出)这两个术语。再加上很明显需要的初始化和销毁操作,一共有四个操作是我们需要的。在加上我们可能会需要用到的empty和full,用来判断栈是否为空,或者是否满,完整的操作如下:
struct Stack{
Stack();
~Stack();
void push( int n );
int top_element() const;
void pop();
bool empty() const;
bool full() const;
};
我们增加了一个top函数,用来获取栈顶的元素,也就是说把pop这个函数分成两步来做。 这么做有两个原因:
- 有时候你确实需要只看不拿,例如如果你对Windows消息队列(虽然他是队列,但也同理)比较清楚的话,你应该知道有一个
Peek函数,就是用来“偷窥”一下,但不进行操作。 - 更为重要的一点是出于对函数功能单一化的要求,即一个函数只做一件事。
为什么函数功能要单一化
设想一下这种可能性,你成功地将元素弹出,但元素赋值失败,无法返回。虽然本例中这种情况不会出现,但对于复杂一点的数据类型这完全可能。
反之的可能性也是有的,即你成功地取出了元素,但弹出这个操作失败了。
此时你处于一个非常尴尬的薛定谔状态——既对,又不对。
pop这个操作本来应该是要么全成功呢,要么全失败的。我们把这种操作叫原子操作。而成功一半,对函数来说就处于两难的境地。
所以函数功能单一化的一个很重要的原因在于:保证函数操作的原子性。
当然除了这个之外还有其他好处,你们现在不一定能体会。记住一点:大多数情况下单一功能的函数比复合功能的函数要好。所以要好好地规划你的函数设计。
栈的顺序实现
线性表有两种实现方式:连续的顺序表和不连续的链表,对应到栈,当然也可以有两种(事实上不止)不同的实现方式,即顺序实现方式和链式实现方式。我们先看顺序实现方式。
显然我们用一个数组(顺序表)来存放元素,并且元素与元素之间连续存放。
我们将0号元素固定作为栈底,通过调整栈顶指针来实现栈元素的压栈和弹出:
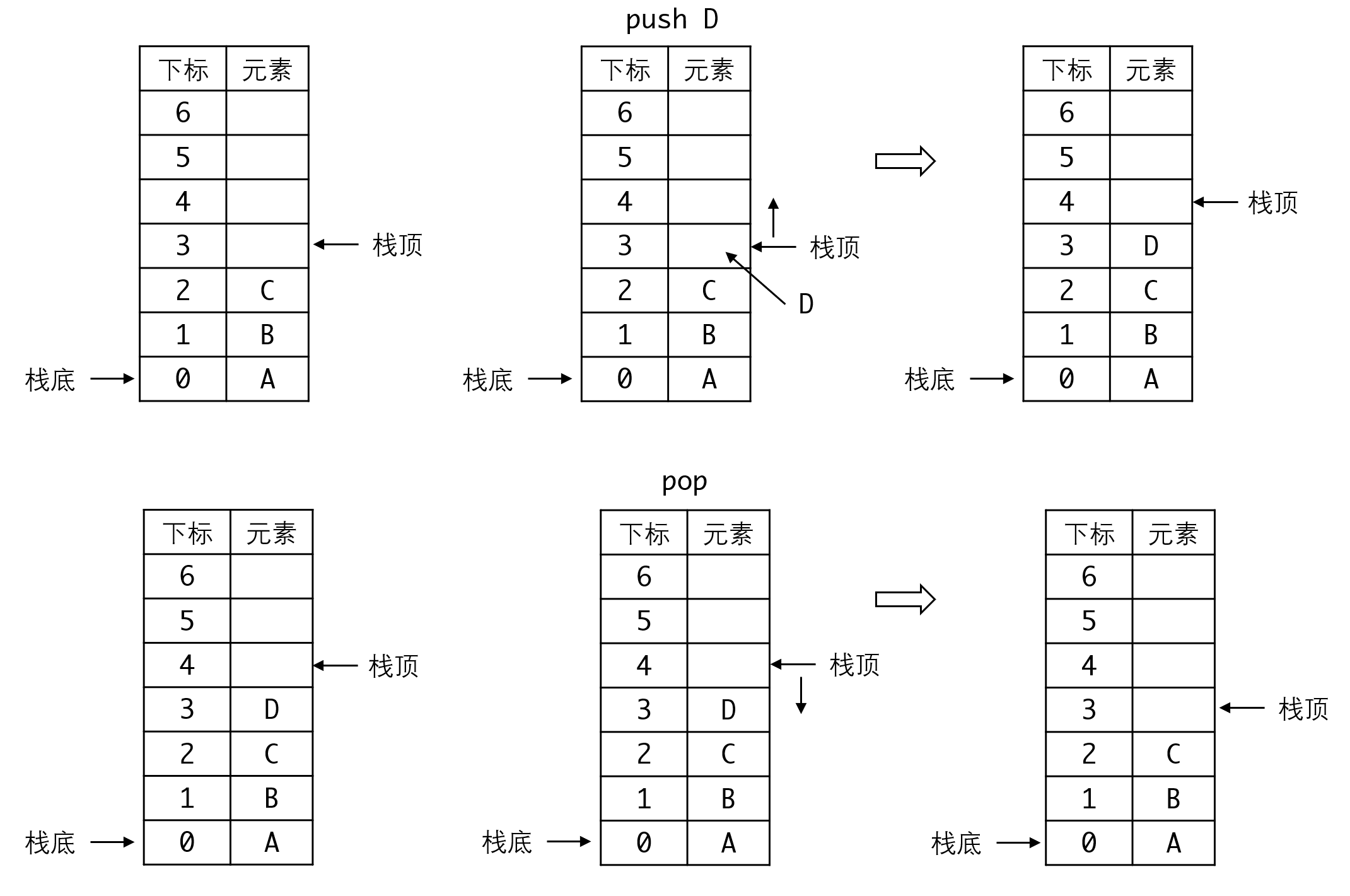
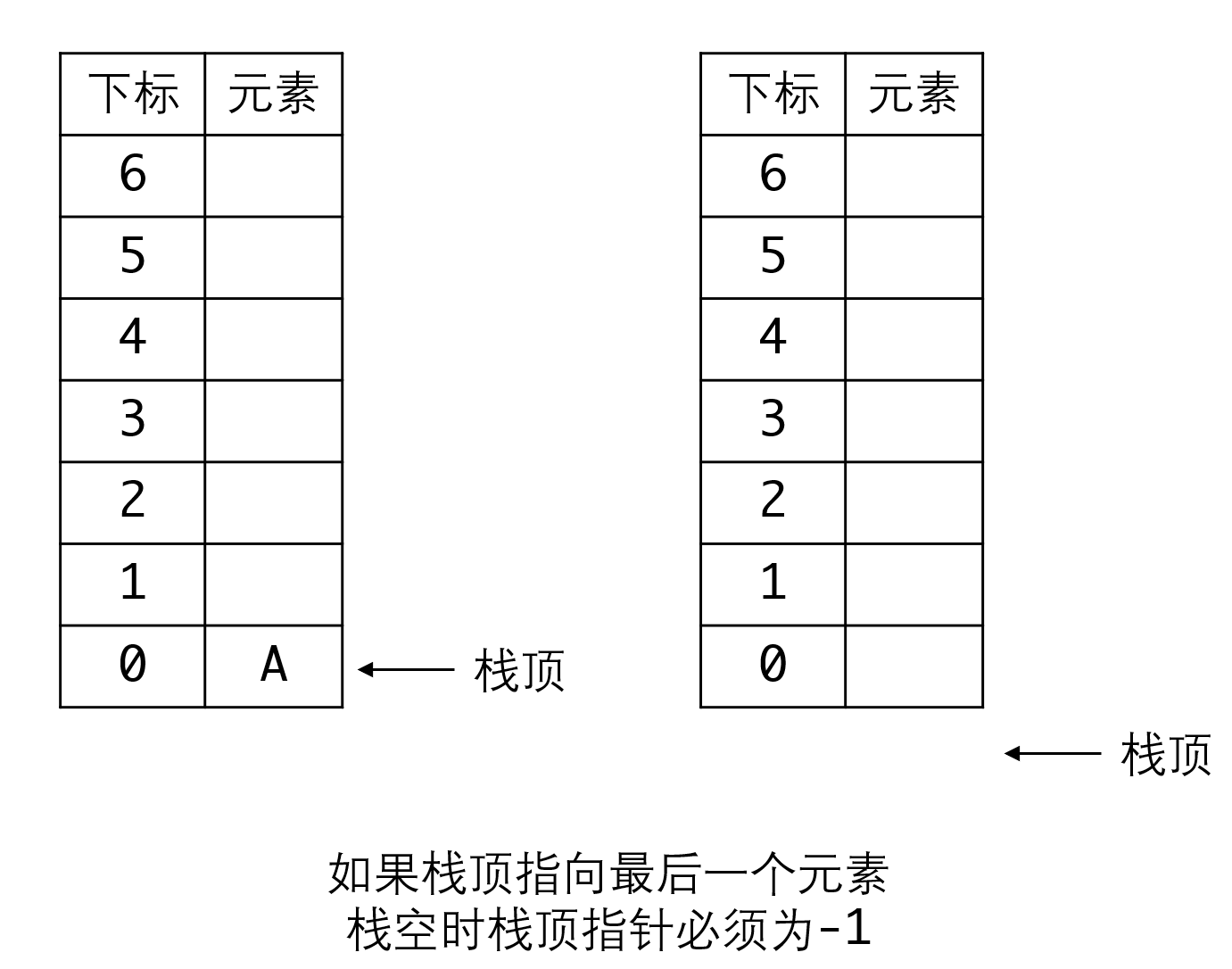
要注意,我们将栈顶指针放在已有元素的下一位,即下一个空格处。这是为了避免栈空时,栈顶指针为负数,与多数人的直觉不符。
由此我们可以很容易写出对应的代码:
struct Stack{
int capacity;
int top;
int* base;
Stack( int capacity );
~Stack();
void push( int n );
int top_element() const;
void pop();
bool empty() const;
bool full() const;
};
这里我们用capacity表示预留的尺寸,top表示栈顶指针,这里简单用下标来表示,base指向预留的内存空间。由于栈底在整个过程中是不会变动的,所以不需要记录栈底,或者说栈底就是base。
Stack::Stack(int capacity){
this->capacity = capacity;
base = new int[capacity];
top = 0;
}
Stack::~Stack(){
delete[] base;
top = 0;
capacity = 0;
}
初始化和销毁很容易理解,不解释。
void Stack::push( int n ){
assert(top!=capacity); // 栈不能满
base[top++] = n;
}
int Stack::top_element() const{
assert(top!=0); // 栈不能为空
return base[top-1];
}
void Stack::pop(){
assert(top!=0);
top--; // 简单将指针下移
}
请注意这里压栈和出栈的下标如何变动,自己在纸上画一下,就很容易理解操作的次序、如何判空和如何判满。
你可能还会需要empty和full这两个函数用来判定栈是否为空,或者是否已满,请自行编写。
函数后面的const是什么?
你会注意到
int Stack::top_element() const;
的定义。
我们已经知道const int*表示指针指向的空间不能被修改。函数后的const与此非常类似,表示这个函数不会修改调用他的对象的内部属性。在上一个例子中,这就意味着在top_element这个函数内部,不会去修改top,base和capacity这三个成员。 也即函数本身是只读的。
const函数除了申明函数只读之外,还有一个很重要的功能,就是提供给const对象调用。假如有这么一个函数:
void f( const Stack& s); // 传入const的Stack引用
那么在这个函数内部,pop、push都是不能调用的。这非常容易理解,因为这两个函数都会修改s的内部状态,如果可以调用,那么s的const就形同虚设了。
但这个函数可以调用top_element函数,因为他已经申明自己不会修改s的属性了。
我们可以通过代码来验证一下栈的LIFO性质:
int main()
{
Stack s(10);
s.push(1);
s.push(2);
s.push(3);
s.push(4);
s.push(5);
for( int i=0; i<5; ++i ){
cout << s.top_element() << " ";
s.pop();
}
cout << endl;
return 0;
}
你会得到
5 4 3 2 1
出栈的顺序与进栈的顺序正好相反。
很显然,顺序表示的栈所有操作复杂度都是
栈的链式实现
顺序存储的一大问题是扩充空间很麻烦,用链式存储则没有这个问题。 由于栈只在一端操作,使栈和单链表堪称绝配:

如图,既然只能在一端操作,那么我们就选择在链表的头部进行操作。 压栈就是向头部插入一个元素,出栈就是把头部的元素删除。
这样我们就可以很容易得到一个所有操作复杂度都是的链栈了。
这里给出链栈的数据定义,请大家自行编写:
struct LinkStack{
Node* head{};
LinkStack();
~LinkStack();
void push( int value );
int top_element() const;
void pop();
bool empty();
};
这里注意,因为栈顶和栈底已经隐含在链表的数据结构中了,所以不再需要。此外链栈的空间只受内存空间的限制,可以认为是无限大,所以就不需要full函数了。
队列
队列的概念
队列更是我们现实中非常常见的情况,相信大家已经非常熟悉了

还有比如我们在公交车上,总是从前门进,后门出,如果人员的次序不发生变化的话,也是一种队列。
排队是为了公平,让先来的人先得到服务。队列也一样,总是先来的元素先出来。 因此队列是一种先进先出(FIFO, First In First Out),或者后进后出(LILO,Last In Last Out)的数据结构。相对栈来说,他是一种很“公平”的数据结构。
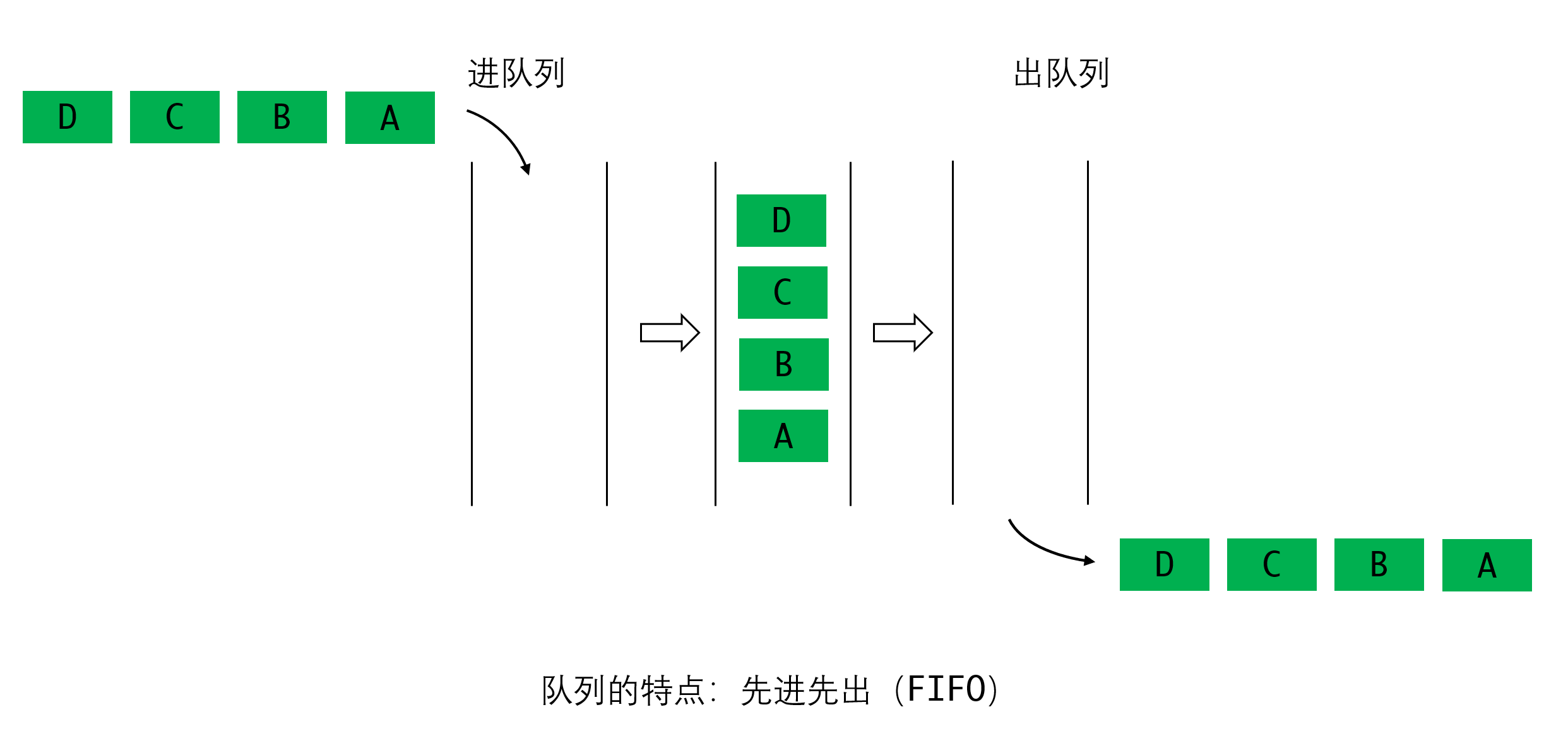
我们可以看出,进队列的次序和出队列的次序是完全一致的,所以队列是保序的,反之栈则会反转数据的顺序。
队列的操作
对于队列,也是仅有进出两个操作,加上初始化和销毁。他的操作与栈非常类似:
struct Queue{
Queue();
~Queue();
void in( int n );
void front_element() const;
void out();
bool empty() const;
bool full() const;
};
这里in和out分别代表进队列和出队列。我们约定从队尾插入元素,从队头取出元素,这与我们的日常直觉相符。因此还需要一个front_element来获得队头的元素。将取出和获得值这两步分开执行的原因上面已经提过了,这里不再赘述。
队列的顺序实现
和栈一样,队列也可以选择顺序实现和链式实现,但和栈不同的是,队列的两种实现都要稍麻烦一点。 顺序存储依然要我们预先分配空间,并给出两个对头和队尾两个指针:
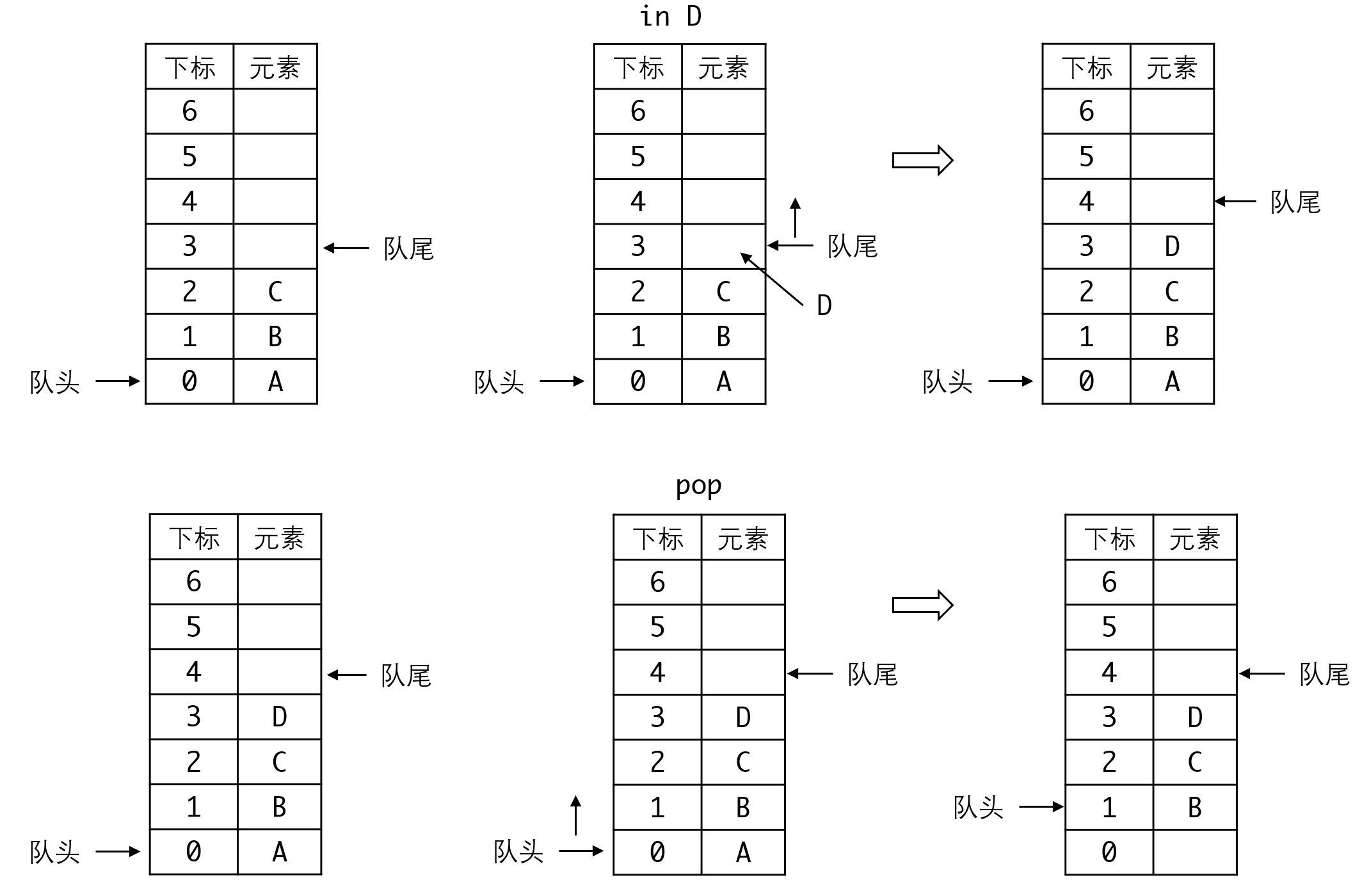
元素进队时,尾指针向后(高下标方向)移动。但与栈不同的是,当取出元素时,是头指针向后(高下标方向)移动。
你很容易发现问题,两个指针都向后移动,说明空间总在持续的缩小,很快预留的空间就不够用了。
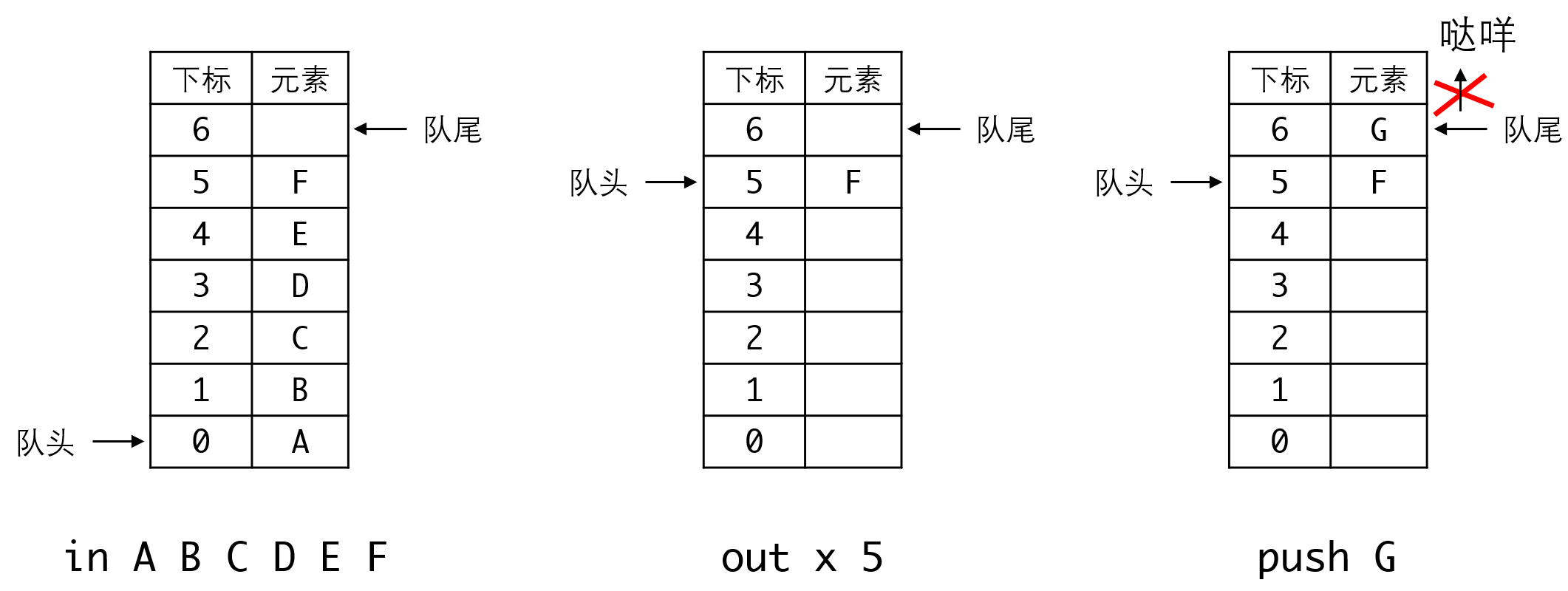
以这张图为例,in7次之后,out6次,照理说此时我们的预留空间还有6个空位,有足够的剩余空间插入新元素,但此时队尾指针已经触及整个空间的尾部,无法再加入新的元素了。
因此我们必须把已经释放的空间利用起来,一个办法当然是每次头指针向上移动,我们就把数据拉下来,但这种方法必须移动所有元素,会导致出队列的复杂度变为:
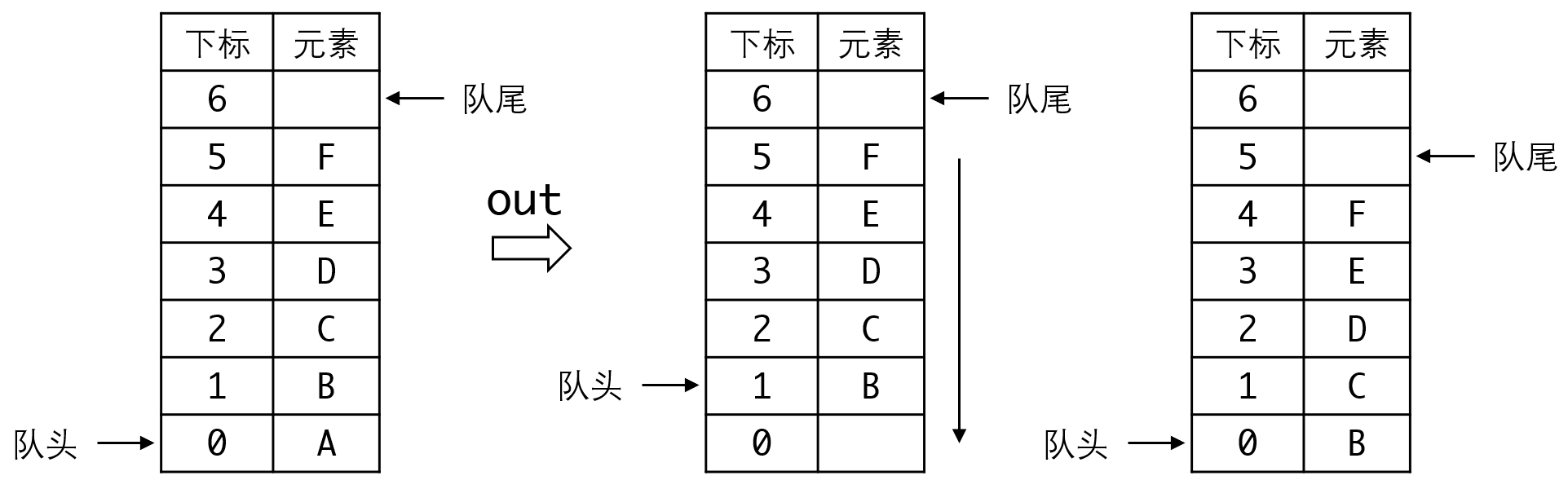
解决方法也很简单,实际上这个思路再我们解决第一个菜鸟问题的时候就有了,将整个队列视为一个环状结构:当指针越过整个空间时,就从头开始:
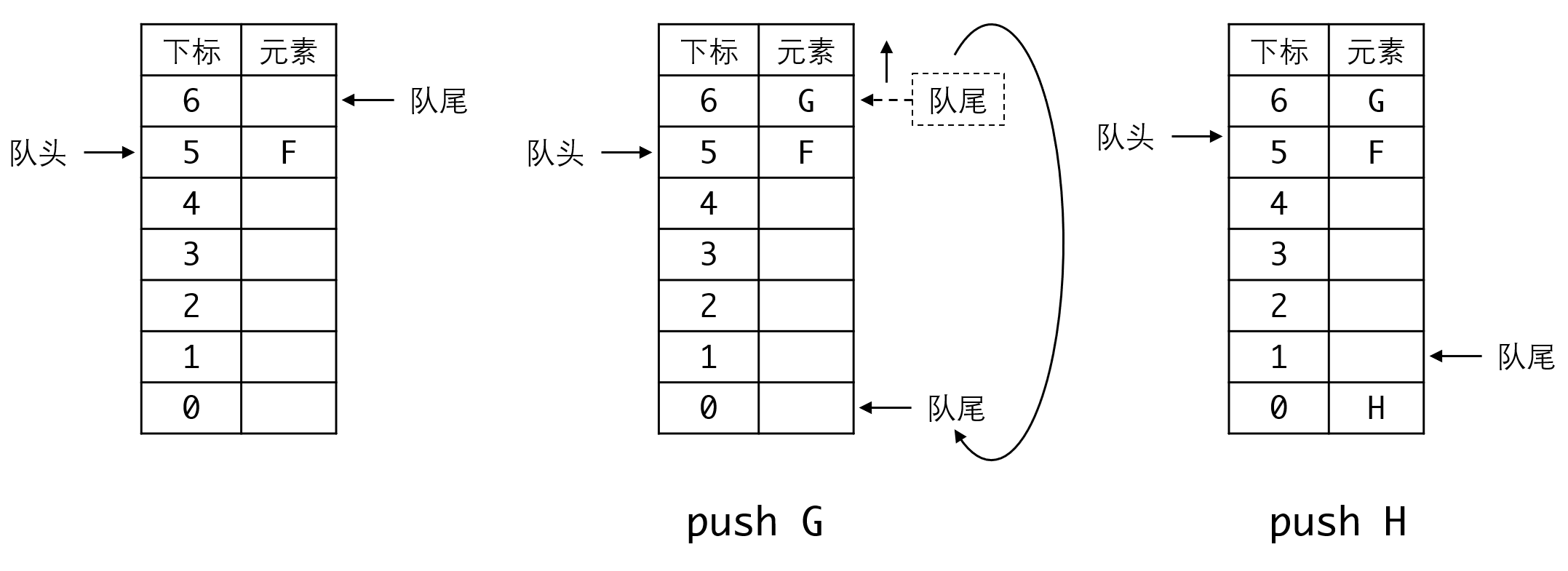
所以我们可以这样写:
struct Queue{
int* data{nullptr};
int front;
int rear;
int capacity;
// ...
};
和栈只需要一个top不同的是,我们需要front和rear两个指针来记录头部和尾部的位置。
那么我们可以这样写in和out函数:
void Queue::in( int n ){
data[rear] = n;
rear = (rear+1)%capacity;
}
void Queue::out(){
front = (front+1)%capacity;
}
这里用%来进行循环队列的下标计算,这是非常常用的技巧,可以避免if语句,代码逻辑也会更简洁。
但这种设置会有一个很大的问题,就是队列满和空要如何判断:
![]()
从上面这张图我们可以看出,无论队列是空还是满,头指针和尾指针都指向同一个空间。这就让我们无法判断一个队列到底是空,还是满了。解决这个问题有两种方法:
- 额外记录一个当前队列里元素的数目,跟
capacity对比就可以知道是空是满。 - 保留一个空格不用,这样满和空时指针的位置就不同。
![]()
如上图,我们保留一个空格不用,这样就可以区别空队列和满队列了。
这里要注意满队列的判断条件,要注意有可能出现队尾指针在最后一个元素的情况,因此需要对rear+1进行一个%才正确。
此外还需要注意一点,第二种方式多占用了一个空格。因此当用户申请n个空间的队列时,你需要分配n+1个空间才能满足使用。
那种方式更好
我们简单对比下两种实现方式
从空间开销看,第一种方式需要记录一个额外的参数,第二种实现方式需要一个额外的空格。在我们这个例子里,开销是相同的。但实际使用中一般元素不会只有一个简单的int,因此多数情况下第二种方式会占用更多的空间。
从逻辑上,第一种方式的缺点是,你需要单独维护一个size参数。会增加代码,同时也比较容易出错——因为满空判断上,逻辑(队列元素是否占满)和实现(通过额外参数判断)是分离的。 第二种方式逻辑和实现是统一的,这点比较不容易出错,不过判满的条件也比较复杂,比较容易写错。
从我个人的角度我会更倾向于第一种。
请大家自己实现一下具体的代码。
队列的链式实现
队列也可以用单链表来实现。但我们需要思考下头指针和尾指针要怎么放。
如果像栈那样,在头部插入,那么就必须从尾部取出,即尾指针放在头部,头指针放在尾部。这样操作会比较符合我们的直观感受,因为队列元素是按顺序存放的。但这种方式在删除元素的时候就会很麻烦:
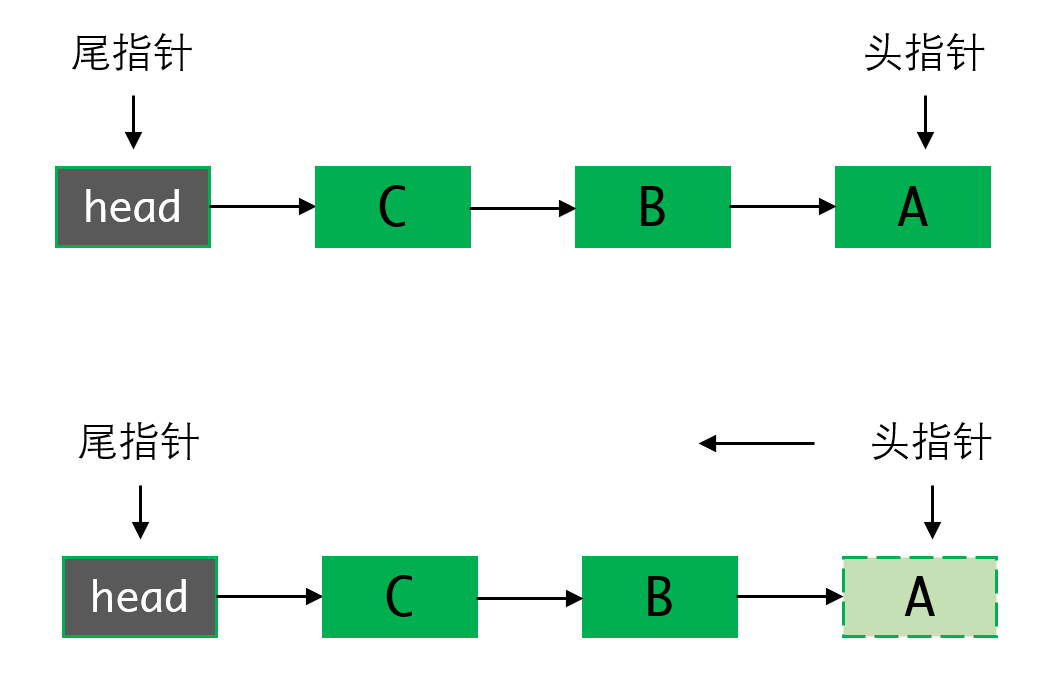
如图,出队列时,要删除头指针指向的A,并把指针向前移动。但对单链表来说,只能向前走,不能回溯。这样就只能从头指针开始向后遍历,得到一个复杂度是的算法。
正确的做法是把头指针放在头部,同时记录尾指针。这样在头部进行删除,在尾部进行添加。由于我们记录了尾指针,所以在尾部添加的复杂度是,在前面头部删除的复杂度也是
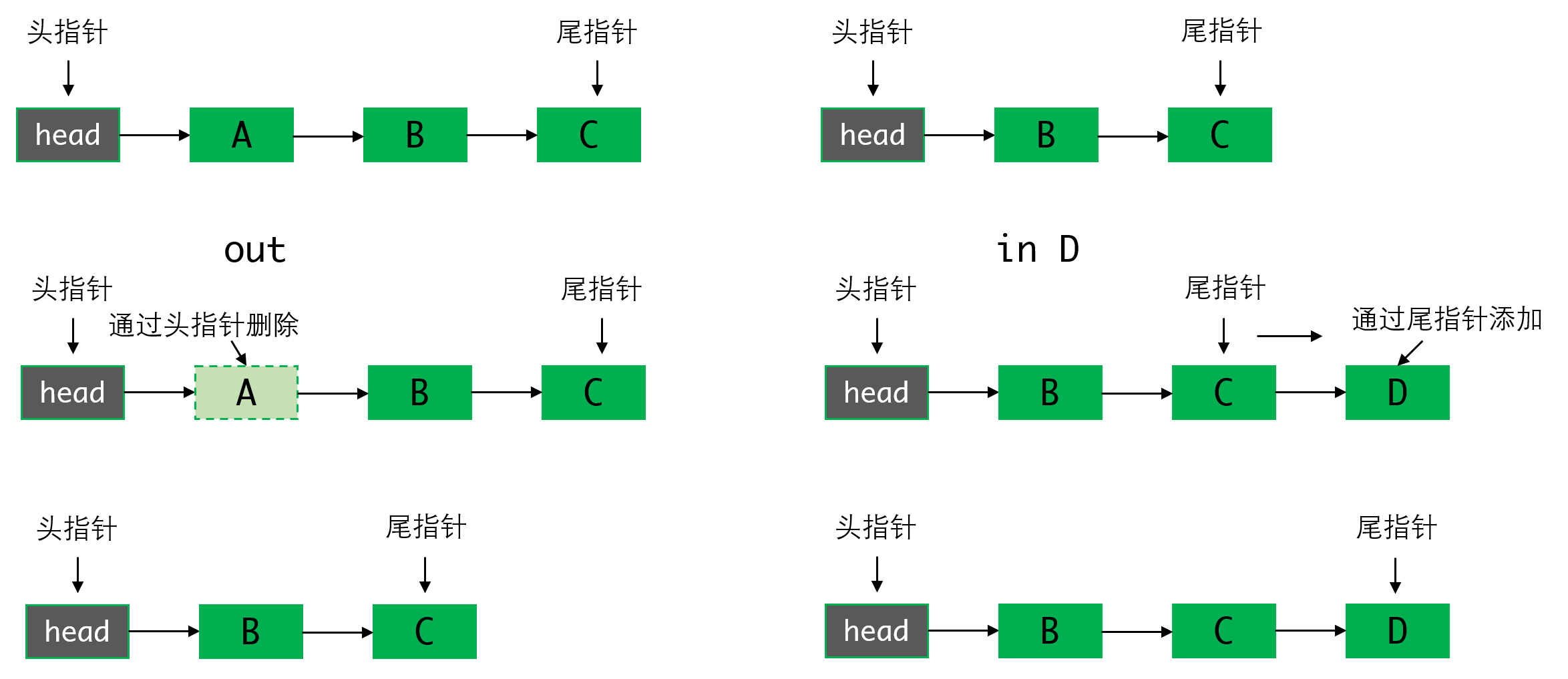
我们可以写出比较简单的代码:
void LinkQueue::in( int n ){
rear->next = new Node;
rear->next->value = n;
rear = rear->nxt;
}
void LinkQueue::out(){
Node* node = front->next;
front->next = node->next;
if( node == rear ){
// 思考下,这里要怎么处理?
}
delete node;
}
这里要注意的是,当队列里只剩一个元素时,此时rear指向该元素。再次出队列,此时需要修改rear指针,否则rear会指向一个即将被销毁的空间。思考下,此时rear要指向谁,这也关系到如何判断队列为空和初始化时rear应该指向哪里。
这部分代码请大家自行编写。
实现方式对比
栈和队列都有链式和顺序两种实现方式。
顺序实现的优点在于:
- 直观,容易操作
- 内存一次性分配,不容易产生内存碎片
- 相对链式存储,每个元素占用的空间更经济
缺点在于:
- 扩容不方便,空间受限
- 需要预留空间,可能造成浪费
链式存储的优点在于:
- 空间不受限制,不存在满的情况
- 不需要预留空间,空间利用率更高
缺点也很明显:
- 内存多次分配,容易造成内存碎片
- 每个对象都需要一个额外的
next指针,单位空间比较大
实际应用中,会采用折衷的方式来实现,具体可以参考C++STL中的实现。