高级排序
高级排序
前面学习的三种排序算法最大的问题是慢。他们的算法复杂度都无法突破,在序列数量超过一定规模之后,算法会慢到无法接受。大家可以试试用插入排序或者冒泡排序对10万左右的数据进行排序,此时算法的延迟已经可以被明显地感受到了。对于更大量的数据,我们需要更快的排序算法。
本节介绍的所有排序算法,时间复杂度都比小,也是现代更加常用的更快的排序算法。
希尔排序
希尔排序是对直接插入排序的改进。从直接插入排序的优化中我们可以知道,一个序列越接近有序,就越可以把中间的过程优化掉,从而获得更好的效率。希尔排序的思想是以步长从大到小进行多次插入排序。在算法进入数据量比比较大的小步长排序时,由于序列已经在比较高的步长上预先进行了排序,因此序列已基本有序,从而降低大数据量下排序的工作量。
希尔排序需要选定一组步长的间隔,且最后一个步长必须是1。一般我们会选择互质一组数字,这从下面的讨论中可以很容易地发现这样做的原因。
算法描述
假定我们选择的步长序列是5 3 1,那么我们的算法要执行三趟,每趟都在对应的步长上执行插入排序:
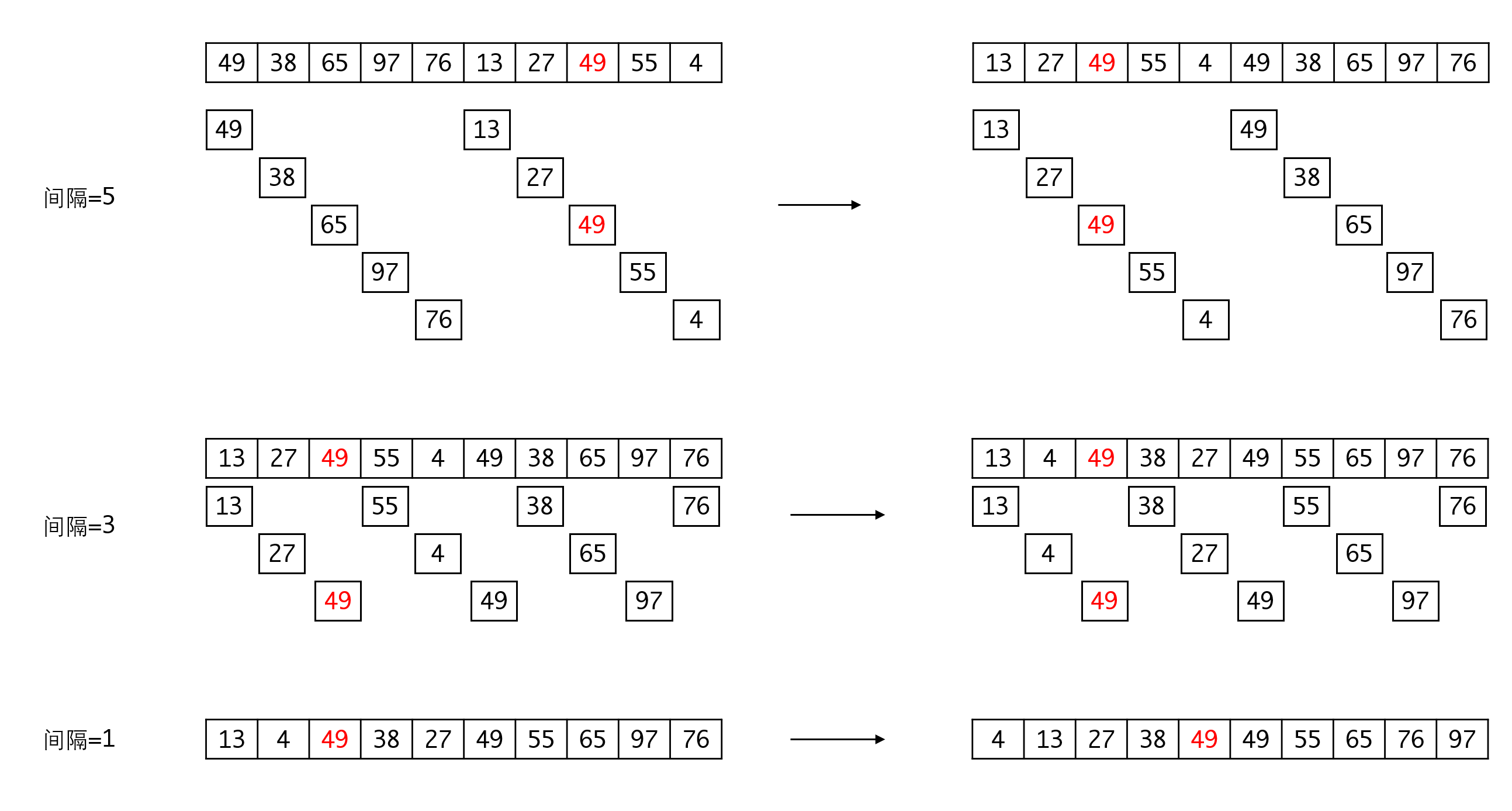
从这个过程大家也很容易看出步长两个限制条件的原因,最后一个步长是1,是为了保证最后会执行一次完整的排序,否则就得不到有序的结果。而选择互质的步长,是为了避免重复计算,比如如果我们选择4和2的两个步长,那么在执行步长为2的排序时,有一半的工作已经在4里完成了,浪费的计算量。
请小心边界
希尔排序的实现需要对细节比较注意,因为步长通常不是序列长度的因数,就导致有些步长下如果处理不好会比较容易越界。比如上面的例子中,间隔为3的这一趟,三个组的元素数目并不相同,这种情况下如果你没有很好地处理,很容易发生越界问题。
算法分析
时间复杂度:希尔排序的时间复杂度很难有一个清楚的结论,我们只知道他跟序列的选择有关。有一些研究指出仔细地选择序列,可以保证一个的平均复杂度。但可以肯定的是希尔排序的复杂度低于,是人类发现的第一种突破的排序算法。
空间复杂度:希尔排序底层都是通过插入排序实现的,所以他的空间复杂度也是。
稳定性:从上面的例子我们就可以看出希尔排序不是一种稳定的排序算法。后面大家会发现,只要是跳着选择的排序算法,都是不稳定的。
适用范围:步长划分需要对序列进行随机访问,因此希尔排序不能应用于链式结构,事实上所有需要跳着选的算法,也都无法应用于链式结构。
希尔排序的复杂度依然是指数式增长的,随着数据量的上升,他的计算量也会快速上升。因此目前已经很少应用了,但他的思想依然是值得我们借鉴的。更快速的排序算法,需要下面三种级别的算法来实现。
快速排序
当一个算法在同级别的算法中被冠以快速的名头,我们就应该知道他的特点了。快排基本上是下面三种算法中平均速度最快的一种。
快排是分治思想的绝佳体现,我们先看他如何实现再来讨论他为什么“快速”。
基本思想
快排的主要思想是选择一个元素为轴(pivot)。一趟处理中我们要将比轴大的元素都移动到轴的左边,比轴大的元素都移动到轴的右侧。这样轴就把元素分割成两个部分,再对这两个部分递归执行上述操作,就可以完成排序。
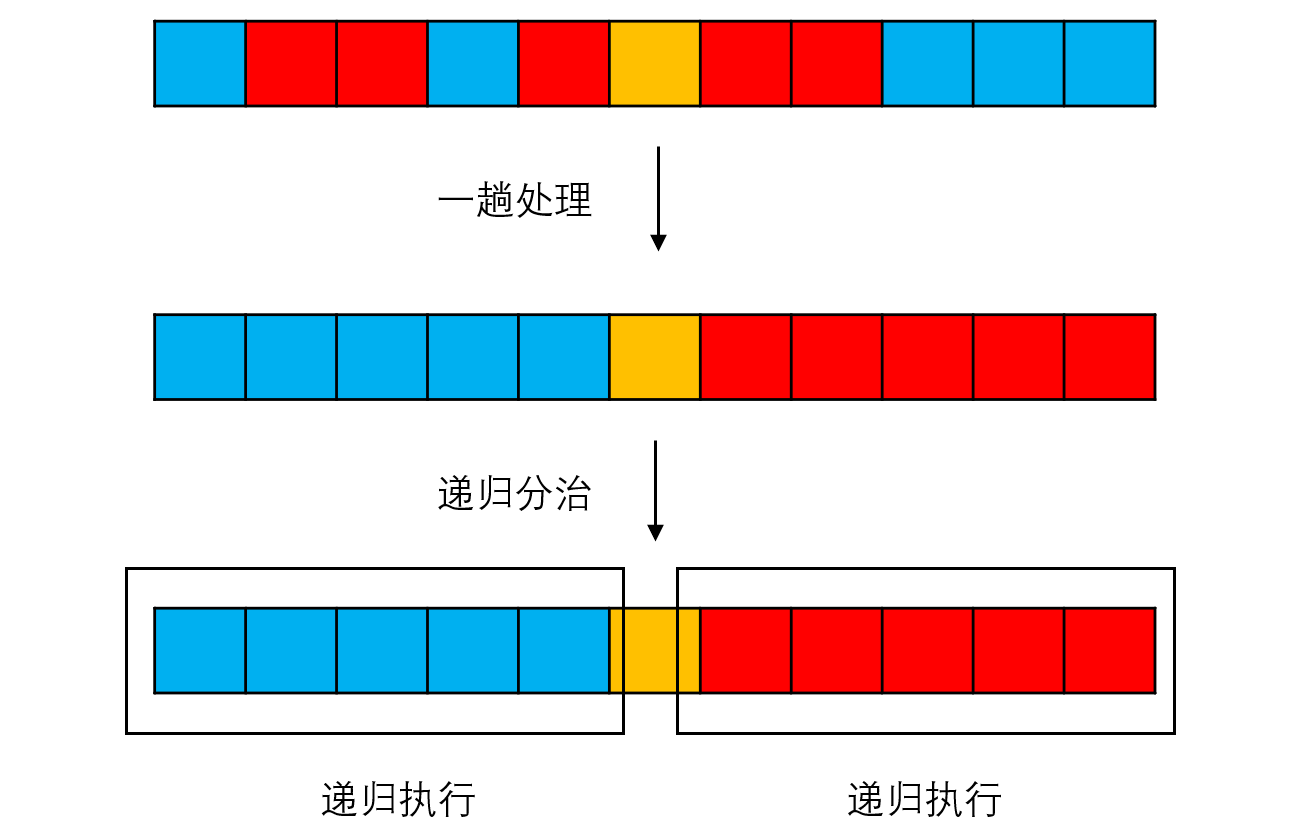
那么问题就来到要如何完成这一趟处理,有两种比较普遍的算法来执行,我们先看书本上的这种。以下的讨论中,为了方便讨论我们都选择第一个元素作为轴。
交换空位法
如果我们把轴取出来,此时就出现了一个空位。我们通过这个空位就可以进行腾挪,从而满足我们的要求。
![]()
注意这里不需要真的生成一个空格,只需要把轴的元素放在对应的格子里,最后当low和high指针都指向同一空间时就可以停机了。
最后我们可以看到,轴前面的元素都比轴小,轴后面的元素都比轴大,一趟处理结束。
双指针法
另一种常见的处理方法是用双指针:
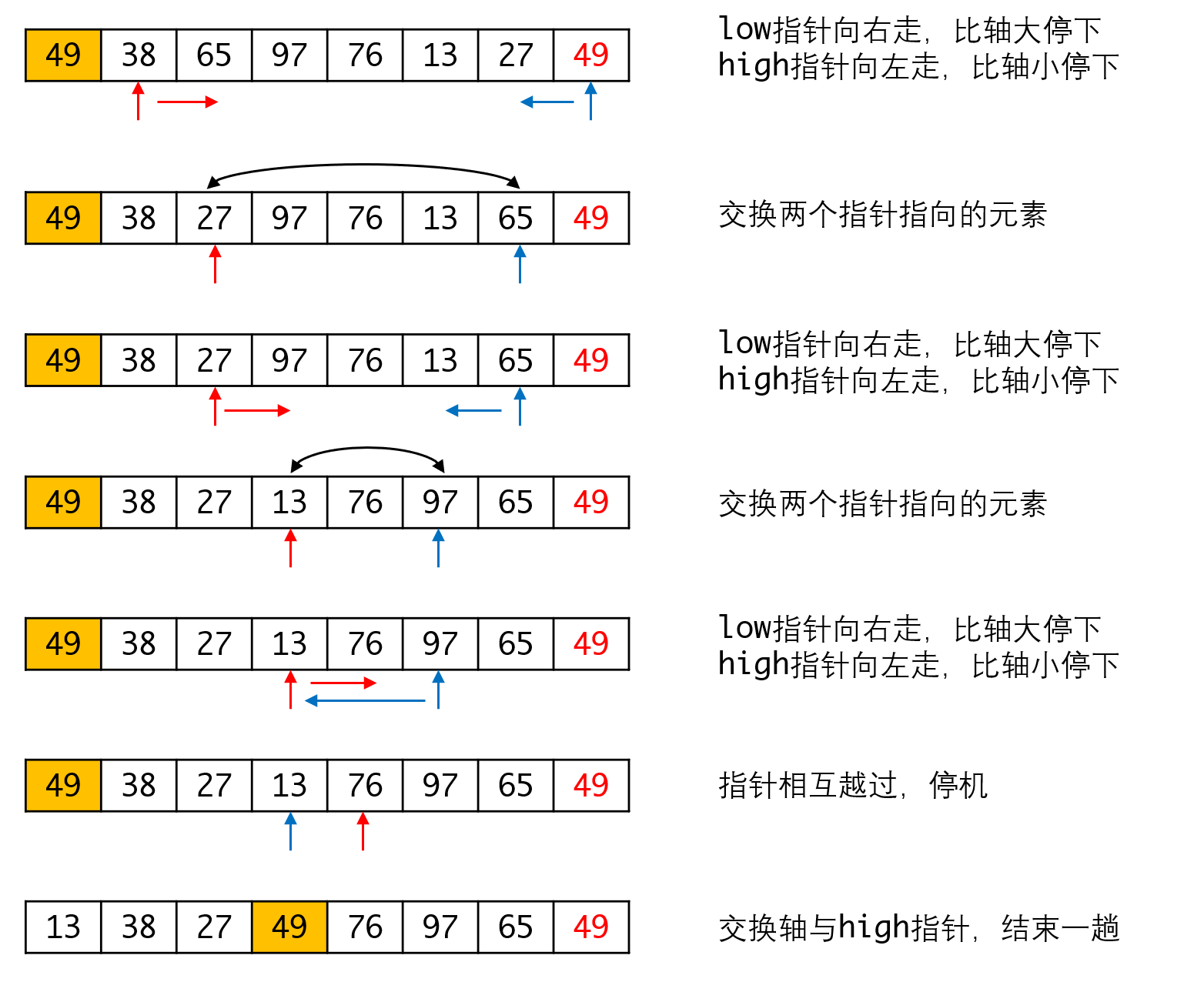
最后的结果虽然跟上面的方法不完全一致,但轴的左侧也都比轴小,右侧也都比轴大,符合要求。
在一趟处理之后,轴把元素分为两个区间,再在这两个区间里递归处理,最后就可以得到排序好的序列了。
算法讨论
算法复杂度:快排每一趟的时间复杂度显然是,所以时间复杂度取决于算法会执行几趟。在平均状态下,我们可以认为算法每次都可以把序列分成两部分,所以执行的次数是。总体拼接起来,快排的算法复杂度是。这也是我们目前为止知道的最小的平均复杂度。
但考虑一下整个序列都是有序的情况:
1 2 3 4 5 6 7 8 9
我们每次都选择第一个数字做轴,此时第一回合算法将区域分成两个部分,但第一个部分有0个元素,而第二个区域有n-1个元素的区域。
第二回合,算法会将第二个区域分为0元素的区域和n-2个元素的区域。
以此类推,算法需要n轮才能完成排序。也就是说整个算法需要的时间复杂度来完成。这是最坏情况下的时间复杂度。
对于冒泡和插入排序最好的情况,却是对快速排序最坏的情况,这不能不让人感叹算法世界的奇妙。
从上面的讨论可以看出,排序算法的效率极端依赖于轴的选择,最好的选择当然是选序列的中位数,这样可以正好把区间分为等长的两部分。所以一般来说,轴的选择要十分小心,并衍生出无数的策略(例如浙大陈越姥姥的课,就会选择第一个、最后一个和序列中间元素这三个数的中位数做轴),一般来说我们这里直接选某个固定位置做轴的做法并不是好的做法,只是方便讨论。
另外为了避免递归层次过深导致的不必要开销,在实际的实现中,一般当序列里元素的数目低于某个阈值时,就会转而用插入排序来执行。
空间复杂度:快速排序也是一种交换排序,只涉及元素交换,不需要额外的空间,因此空间复杂度是。
稳定性:快速排序交换元素的位置跳跃式交换、相对随机的,无法控制元素的相对位置,所以快速排序是不稳定的。例如大家可以看看下面的序列
38 13 49 97 76 65 27 49
不管使用上面的那种算法,第一回合后,两个49的相对位置都会发生变化。
适用性:快排的交换是跳跃性交换的,显然顺序表要比链表更容易实现,比如STL的算法sort,就要求容器有随机迭代器。但如果是双链表,我们前面讨论的快排算法也可以比较好的应用。但实际上,单链表也是可以运行快排算法的:
- 选择最后一个节点做轴并保存。
- 遍历一趟,将所有大于节点的元素摘出来并插入轴节点之后
这样就可以完成一趟排序。
所以经过小心的设计,快排也是可以应用于链表。
归并排序
归并排序是另一种非常常用的排序算法,它拥有与快速排序一样的时间复杂度,即,同时还是一种稳定的排序算法,这使他有很广泛的应用范围。
基本思想
归并排序的基本思想与快速排序非常类似,都是以分而治之的方式来对序列进行处理。所不同的是快速排序的分而治之是自上而下进行的,而归并排序是自底向上执行的。归并排序把小序列逐步合并成大的序列,直到整个序列都有序为止。
我们看下面的排序过程:
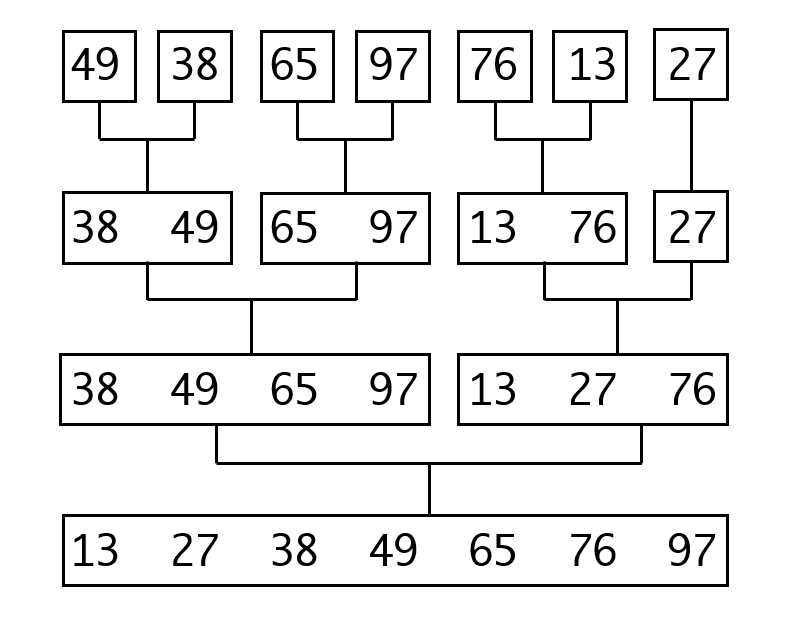
一开始我们把每个元素视作一个序列,将他们合并成一个2个元素的序列。然后2并4、4并8、一路合并下去之后,直到最后整个序列都有序为止。
有序序列合并成为一个有序序列的算法,我们在顺序表算法中已经见到过了。
算法讨论
时间复杂度:有序序列的合并的时间复杂度是,因此一趟处理的复杂度是每一段距离的和,也就是。而显然算法要执行次。所以算法复杂度是,和快排一样。
相比快排,归并排序不同的一点是,他在最好,最坏和平均条件下,都有的复杂度,因为算法的执行方式是固定的。并且他执行的趟数与数据的分布没有关系。
空间复杂度:这点是归并排序和其他比较排序算法最大的不同,归并排序的每一趟,我们都需要一个额外的空间来放置执行的结果。因为归并的过程无法在同一个内存空间内执行。但我们也不需要的空间开销,因为每一趟执行都可以复用上一趟执行的空间来作为结果空间:
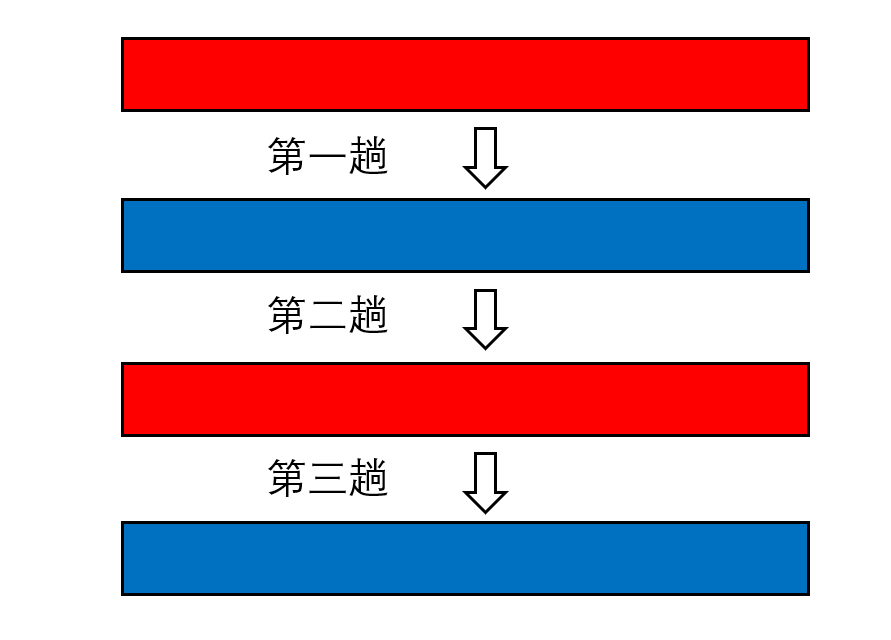
红色和蓝色分别代表两个不同的空间,上一趟的源空间作为下一趟的目标空间,这样交换,就只需要的额外空间开销。
稳定性:归并排序是稳定的排序算法,这是他最大的优点,高级排序中也是唯一一种稳定的排序算法。归并操作总在相邻的两个序列之间执行,因此相同元素的相对位置是可以得到保证的:
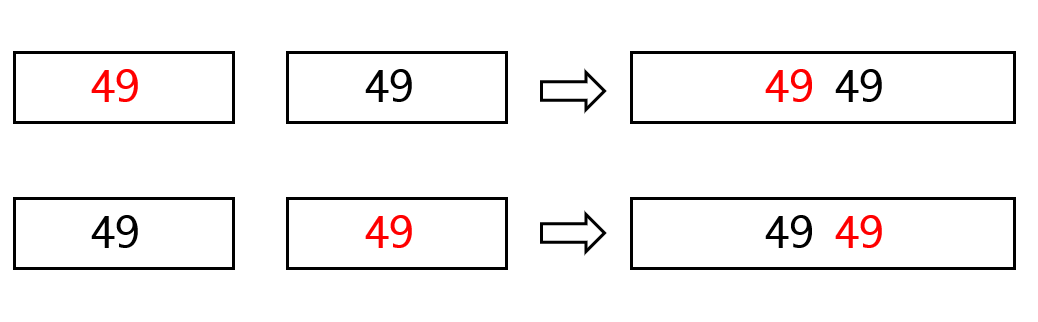
适应性:之前我们讨论有序序列合并时,已经知道这个算法对顺序表和链表都可以适应,因此归并排序算法也可以适应这两种数据结构。
归并排序与快速排序
归并排序和快速排序是最常用的两种排序算法,他们各有特点。从绝对执行速度上来说,快速排序的名字就揭示了其特点。因为快排移动数据的特点,他的数据总是能很快移动到位。归并排序的速度也很快,但有实验表明在数据量比较大的情况下快排会比归并快2~3倍。
但快排对数据的分布有一定要求。前面已经知道,在极端的最坏情况下,快排可能会退化到的复杂度。一般来说数据分布越平均,快排每趟的分割就会越均匀。
归并排序的优点在于两点。第一点是稳定性,归并排序是所有高级排序算法中唯一稳定的排序算法,在需要稳定排序的场合你没得选。第二点也是稳定性,归并排序不像快速排序那样对数据的分布有要求,他不会因为数据而导致排序效率大幅度下降。
归并排序的缺点在于有额外的空间复杂度,这也是所有比较排序算法里唯一一个有空间复杂度要求的排序算法。
堆排序
堆排序是一种选择排序算法。实际上在讨论选择排序时,我们就应该可以想到用堆加速的方式了,因为我们每次都要选择最小的那个元素放到开头,这不就是最适合用堆来实现的方式吗?但这种方式有一个很大的问题,就是额外的空间开销。要把所有的数据都放入堆,就需要一个的空间开销。这就让这种做法显得非常不经济。
堆排序在这个思想上更进一步,他不使用额外的空间,而是在原始的空间上直接进行堆的调整,依次取出来放到合适的位置。
基本思想
堆排序由两个步骤组成,第一步先把序列调整成一个大顶堆。再从这个大顶堆里取出堆顶元素并放到最后。为什么是大顶堆,我们可以从后面的讨论中看到。
堆调整
如果我们把整体序列看成一棵完全二叉树的话,那么我们的调整就要从最后一个非叶子节点开始:
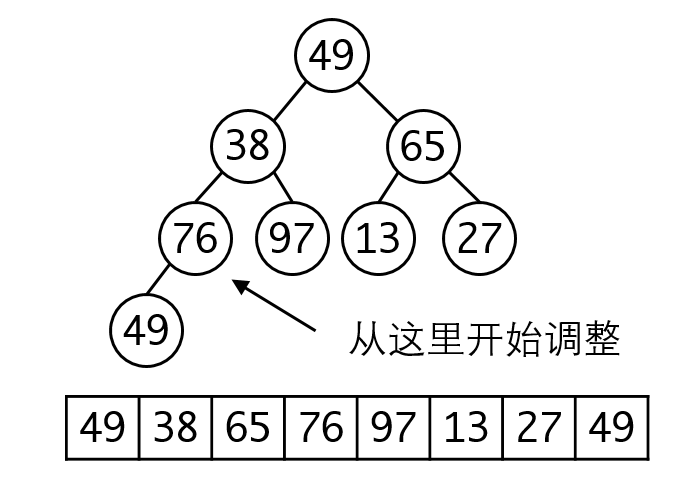
根据完全二叉树的性质,我们可以很容易算出这个点的下标=L/2。
我们要构建的堆是大顶堆,要求根节点比叶子节点大。因此我们向上遍历(非叶子)元素,再向下调整,直到结果符合堆的要求:
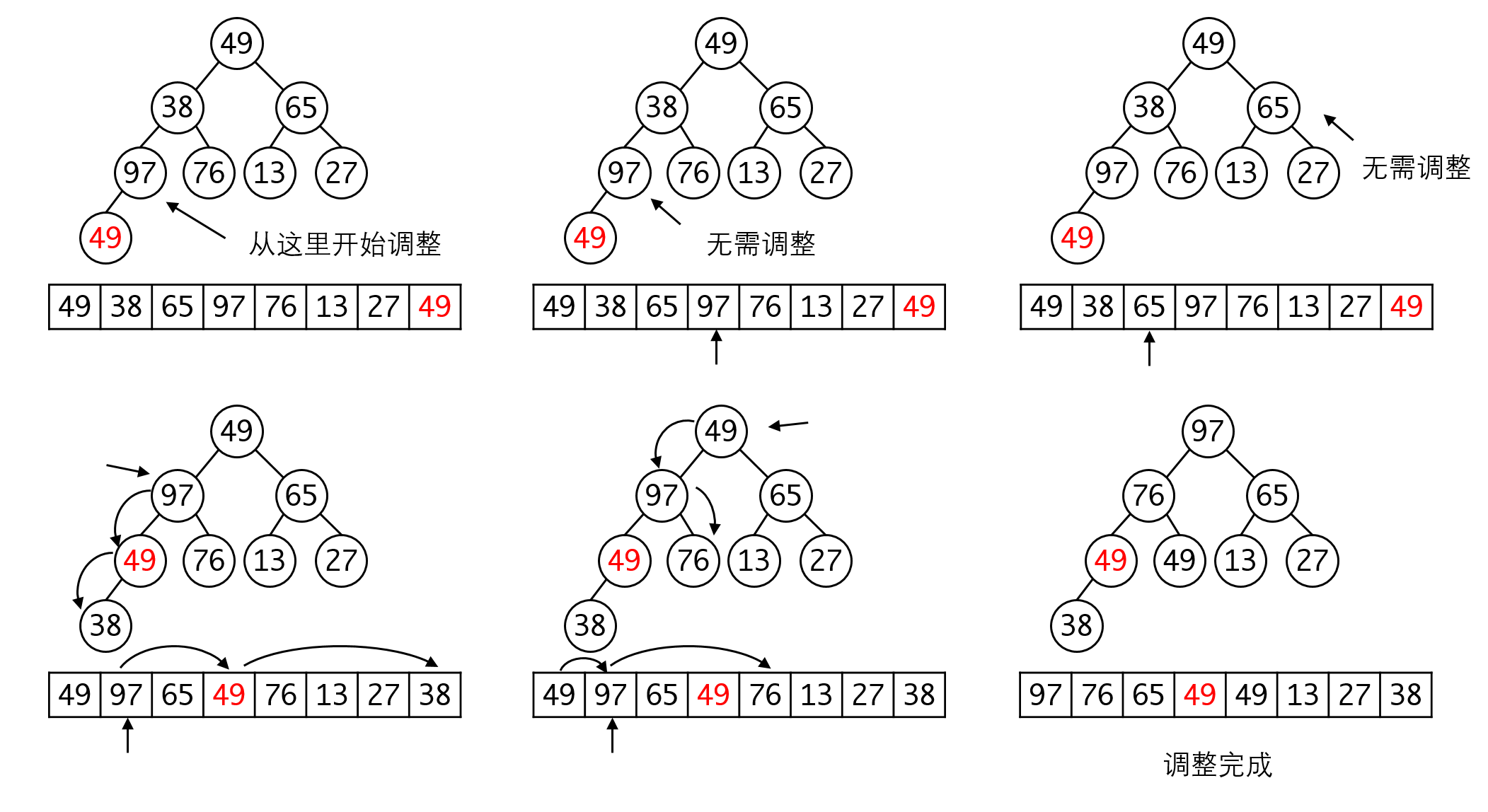
堆调整的方式和堆那章的没有区别。这里要注意的是,因为我们没有守卫元素,此时父节点和子节点的映射公式就会不同:
带守卫的情况:
- 父节点:
- 左孩子:
- 右孩子:
不带守卫的情况:
- 父节点:
- 左孩子:
- 右孩子:
堆排序
堆调整完毕之后,我们就需要将数据依次取出后放到合适的位置。此时我们可以利用堆删除的一个特点:删除时,我们总将顶部元素取出,此时需要将其与最后一个元素交换,再调整堆。注意此时最后一个元素就是整个序列的最末端。此时我们可以看出为何需要用大顶堆的原因——删除时最大的元素会很自然地被放到正确的位置。这个过程和选择排序是一样的,不同的是我们不再需要遍历序列来获得这个最大元素,而是可以直接获得。
移除最后一个元素之后,我们就需要调整堆让堆重新平衡。
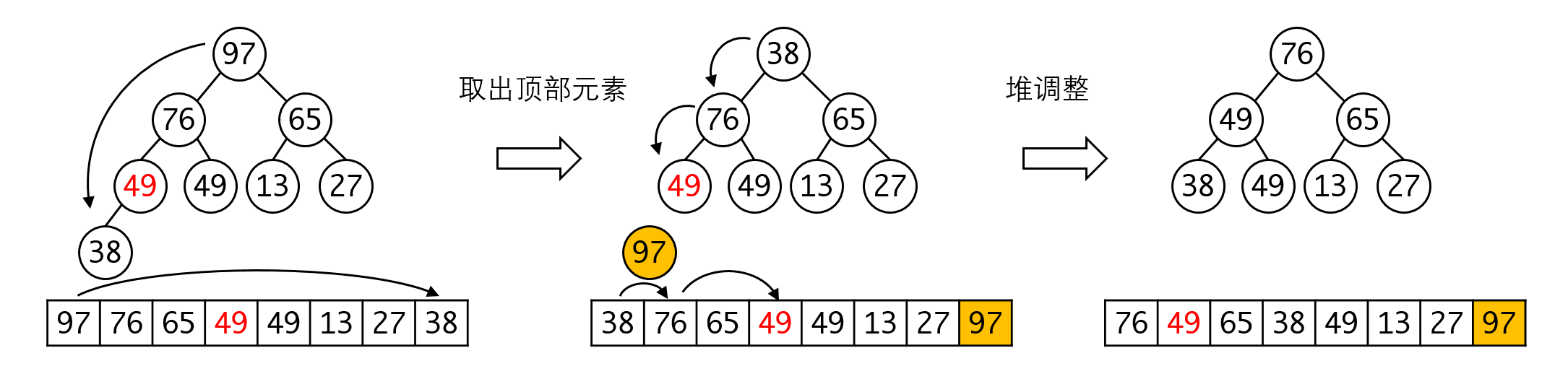
重复这一步骤,直到所有的元素都取出就完成了排序:
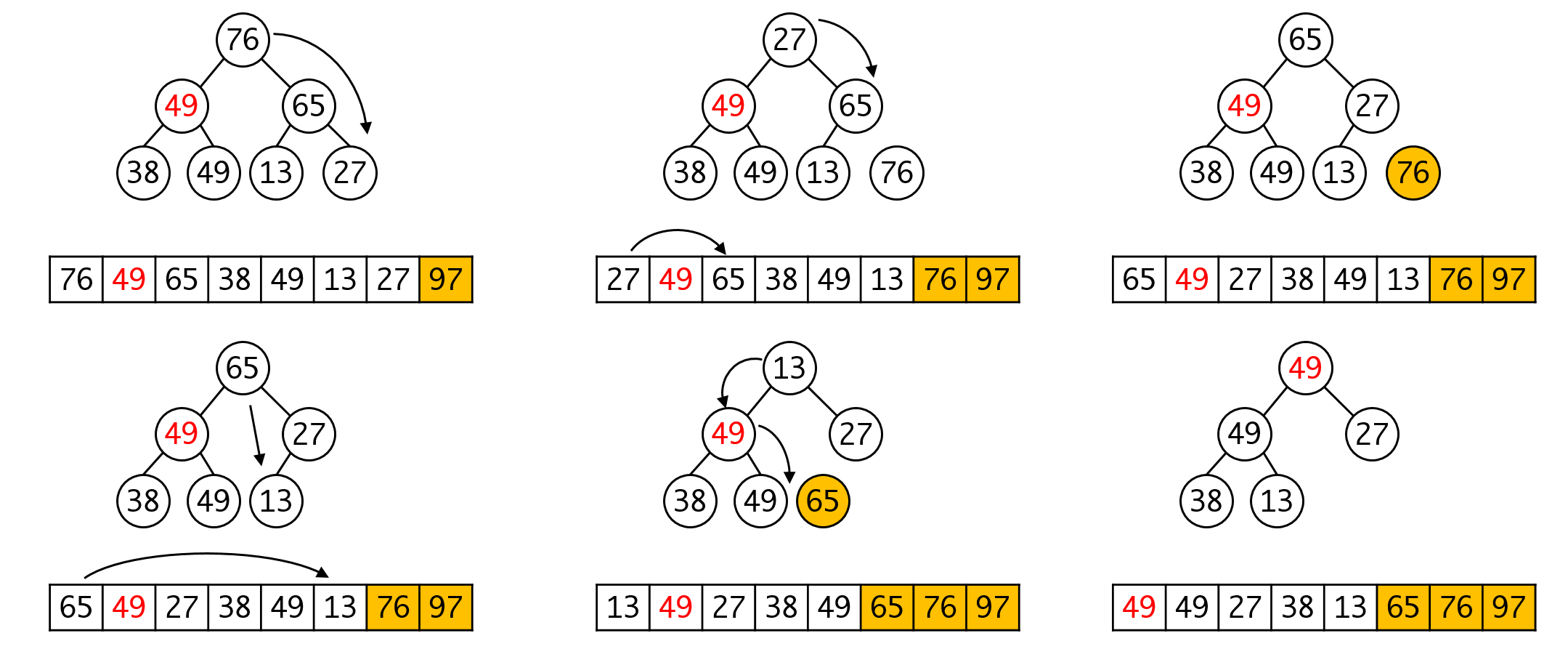
这里给出3个元素的排序结果,剩余的排序过程请大家作为联系自行完成。
算法讨论
时间复杂度:时间开销可以分为两个部分:堆调整的时间和排序的时间。调整堆的时间复杂度看起来是,实际上并不会超过,因为我们并不是每个元素都会进行调整,而是从第一个非叶子节点开始进行调整。而排序的过程每次都是一次堆删除,时间复杂度为,执行次,因此其总体时间复杂度为。和快速排序算法不一样的是,堆排序不存在时间复杂度退化的问题,这是他的优点。
空间复杂度:堆排序是在原地进行处理的,不需要额外的空间,因此空间复杂度是。
稳定性:堆排序的调整是跳跃交换的,无法保证相对次序,所以他是不稳定的。
适应性:堆的构建和删除都需要依赖于顺序结构,因此堆排序无法应用于链式数据结构中。
堆排序是一种非常独特的排序算法:相对快速排序,他不存在时间复杂度退化的问题,稳定地保持在这个级别。相对归并排序,他没有额外的空间开销需求。除了不稳定,听上去真的是一种非常好的排序算法。但实际上堆排序的排序速度可能是这三者中最低的一种。堆调整的特点决定了每次删除,都有很大概率要从根节点一路调整到叶子。这使得他需要非常多的比较和交换,同时又很难优化。因此实际上堆排序的应用范围远不如快排和归并排序。
总结
本章讨论了4种复杂度低于的算法。
- 希尔排序的时间复杂度与步长选择有关,最低可能为,空间复杂度为,不稳定,只能应用于顺序结构。
- 快速排序平均和最好时间复杂度都是,但可能退化到,空间复杂度为,不稳定,可以应用于顺序结构和链式结构(但不好写)。
- 归并排序的平均、最好和最坏的时间复杂度都是,空间复杂度为,稳定,可以应用于顺序结构和链式结构。
- 堆排序,最好最坏和平均时间复杂度也都是,空间复杂度为,不稳定,只能应用于顺序结构。
这四种算法里,希尔排序基本已经不再使用,堆排序的应用范围也很狭窄。应用最广泛的是快速排序(快)和归并排序(稳定,不会退化)。如果对算法的时间要求比较高,且不希望有额外的空间开销,那么就用快速排序。如果不介意空间开销,并希望算法的时间开销尽可能稳定可控,对算法稳定性有要求,那么就选择归并排序。